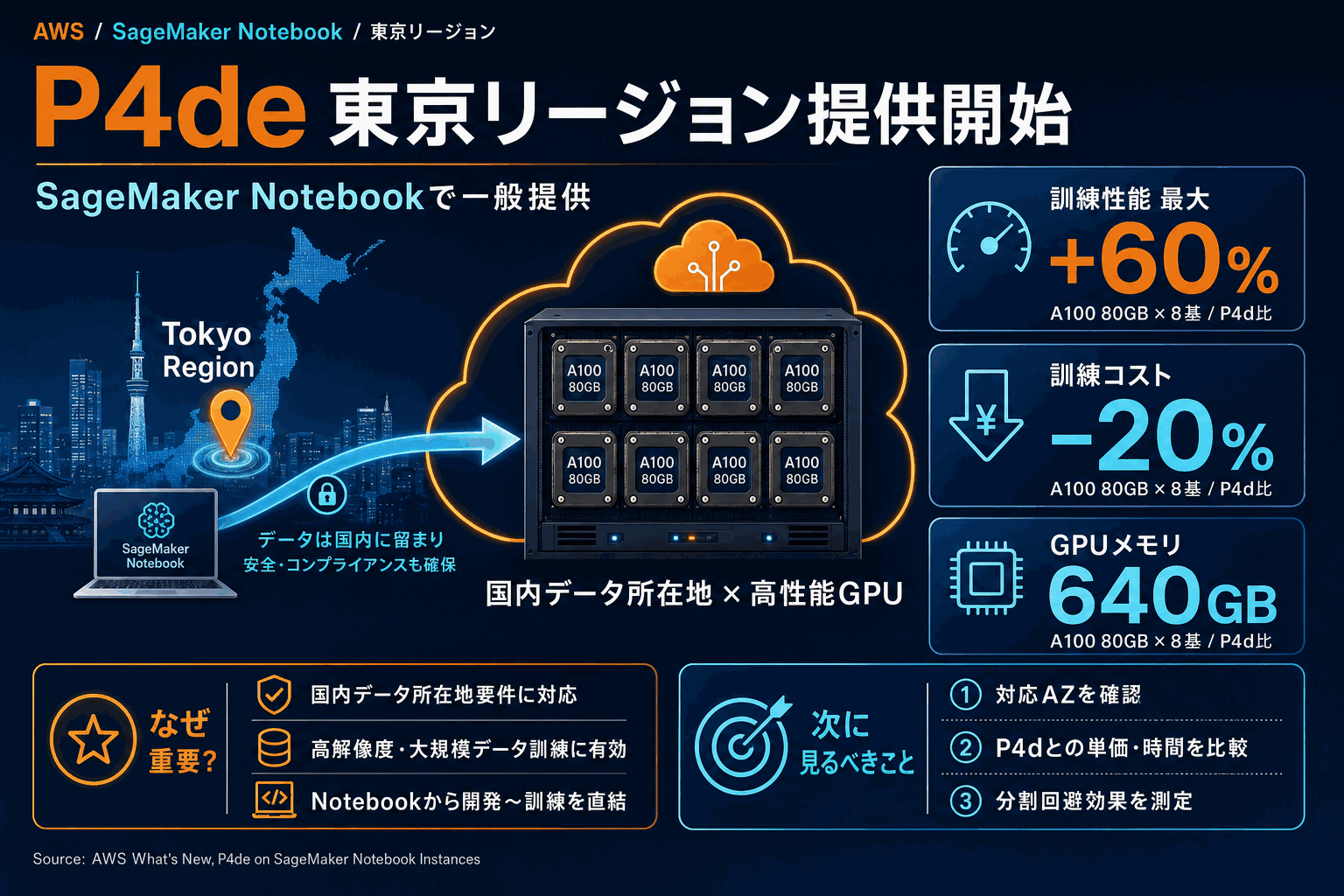
何が東京リージョンで使えるようになったか
AWSはAmazon EC2 P4deインスタンスを、アジアパシフィック(東京)リージョンのSageMakerノートブックインスタンスで一般提供開始した。P4deはNVIDIA A100 GPUを8基搭載し、各GPUに80GBの高性能HBM2eメモリを持つ。公式は次のように説明している。
Amazon EC2 P4de instances are powered by 8 NVIDIA A100 GPUs with 80GB high-performance HBM2e GPU memory, 2X higher than the GPUs in our current P4d instances.
GPUメモリは合計640GBに達し、現行のP4d搭載GPUの2倍となる。SageMaker Studioおよびノートブックインスタンス上でJupyterLab・CodeEditorアプリケーションから利用できる。
性能とコストの具体数値
注目点は、P4dとの比較で示された具体的な数値だ。
The new P4de instances provide a total of 640GB of GPU memory, which provide up to 60% better ML training performance along with 20% lower cost to train when compared to P4d instances.
ML訓練性能が最大60%向上し、訓練コストが20%削減される。これは同じモデルを訓練する際の単価と所要時間を比較する直接的な材料になる。増えたGPUメモリは高解像度データの大規模データセットを扱うワークロードで効く、と公式は明記している。
落とし穴として、公開された性能・コスト数値はAWS側の比較値であり、自社のモデル構造やデータI/Oによって実測値は変わる。移行を判断する前に、既存のP4d訓練ジョブを同一条件でP4deに載せ替え、訓練時間とコストの差を自社データで測ることが必要になる。同日にはClaude Opus 4.8のAWS提供開始も告知されており、東京リージョンの訓練・推論基盤の選択肢が同時に広がっている。