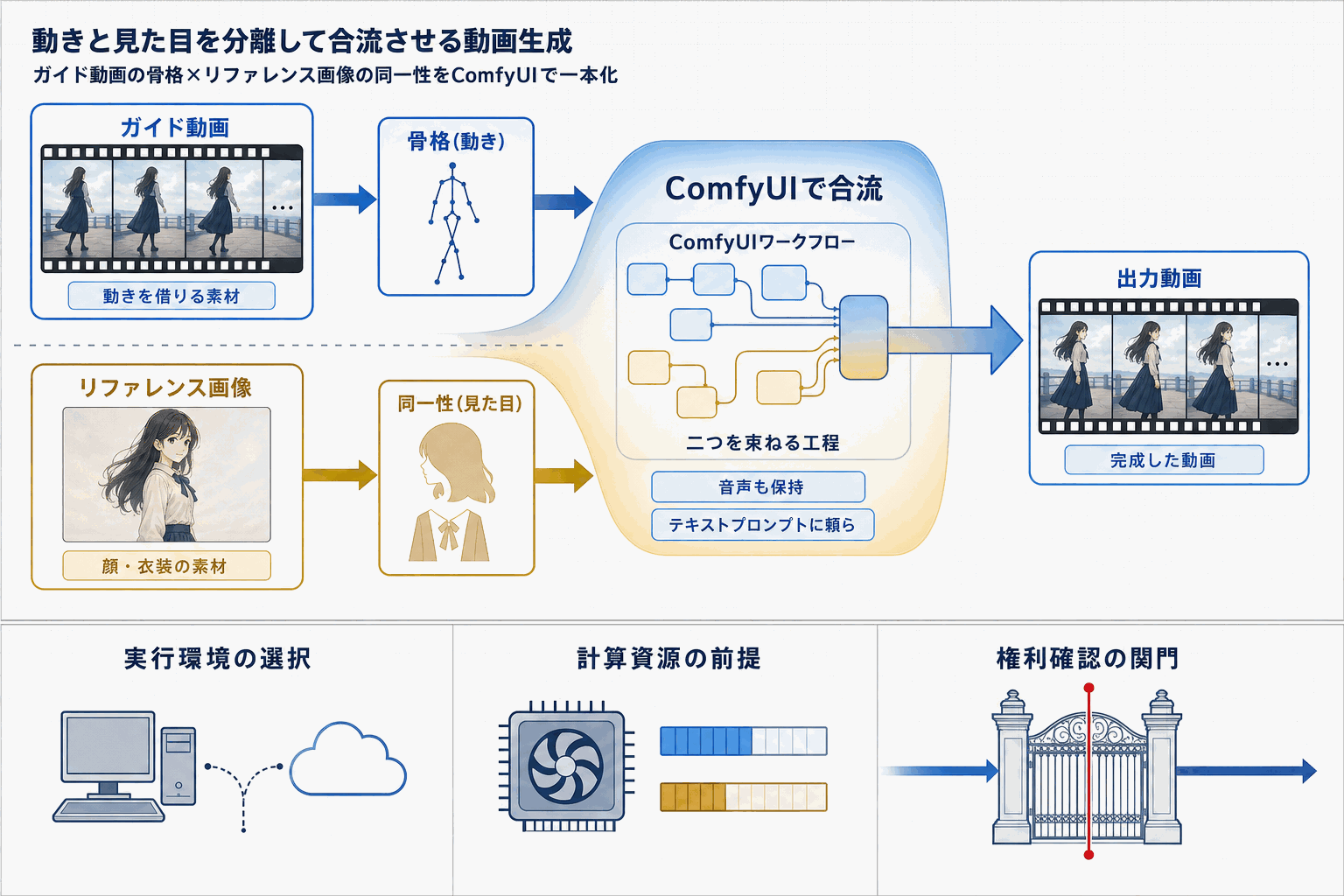
Civitaiで公開された「VACE SkyReels V3 R2V Merge Skeleton-Guided Video Workflow」は、近年急速に整備されてきたオープンな動画生成エコシステムの「組み合わせ運用」を象徴する事例である。
中核となるVACEは、ali-vilabが公開する動画生成・編集の統合フレームワークで、論文「VACE: All-in-One Video Creation and Editing」(huggingface.co/papers/2503.07598)として公表されている。参照画像、マスク、各種コントロール信号を一つのモデルで扱い、生成と編集を分離せずに処理する点が特徴で、GitHub(ali-vilab/VACE)に実装が、Hugging Face(Wan-AI/Wan2.1-VACE-14B)に14Bクラスの重みが公開されている。
ここにSkywork AIのSkyReels V3(SkyworkAI/SkyReels-V3)をマージし、スケルトン(骨格)情報でガイドする構成にしたのが今回のワークフローだ。R2V(Reference-to-Video)、つまり既存動画のモーションを抽出して別の被写体・スタイルで再生成する用途を、ComfyUI系の手元環境で回せる形にまとめている。
読者にとっての含意は三つある。第一に、動画領域でも「公開モデル+配布ワークフロー」で実装する流れが定着しつつあること。第二に、VACE論文・GitHub・Hugging Face重みという一次情報が揃っており、ワークフローの中身を逆引きで検証できること。第三に、リファレンス動画からの骨格転写は、素材の権利処理とライセンス条件の確認が実装前段で必要になることだ。試す前に各リポジトリのライセンスと、入力素材の利用範囲を切り分けて記録しておきたい。