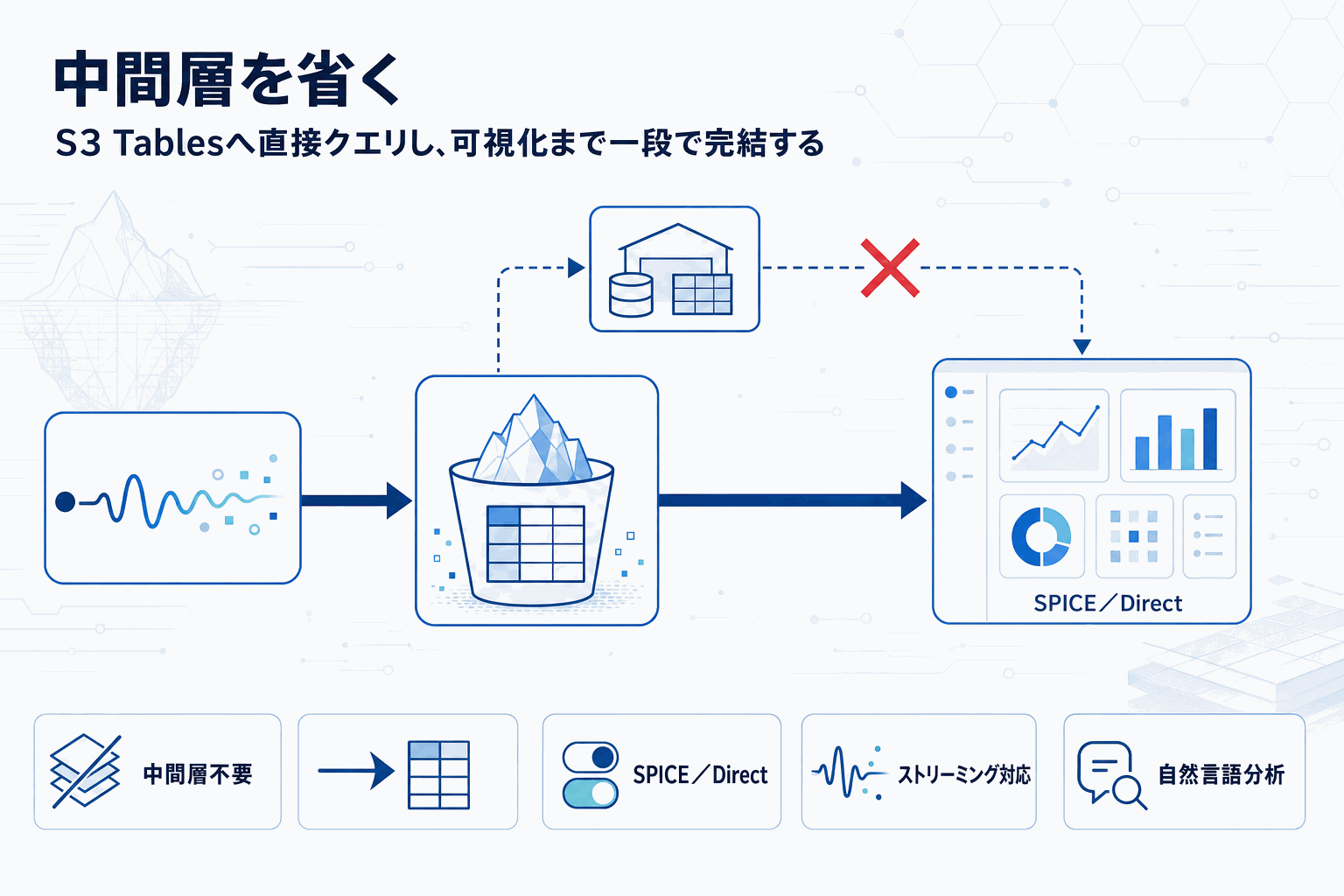
Amazon QuickSightは、Apache Iceberg形式のAmazon S3 Tablesを新しいデータソースとして正式に追加した。これまでS3上のデータをQuickSightで可視化するには、AthenaやRedshift、あるいは別のデータウェアハウスを中間クエリレイヤーとして挟む構成が一般的だった。今回の対応で、QuickSight管理コンソールからS3テーブルバケットのARNを指定するだけでデータソースを作成でき、Icebergテーブルに対して直接クエリと可視化を行える。
動作モードはSPICE(インメモリ取り込み)とDirect Query(都度クエリ)の両方に対応する。鮮度が最優先のダッシュボードではDirect Queryで常に最新のIcebergスナップショットを読み、読み込みコストや応答速度を優先する画面ではSPICEに取り込むという使い分けが、同じQuickSight内で完結する。公式ブログではKinesis Data StreamsやData Firehose経由でS3 Tablesに書き込むストリーミングパイプラインと組み合わせ、金融取引の不正検知のようなニアリアルタイム分析のユースケースが例示されている。
利用条件はQuickSightのEnterpriseサブスクリプションで、エディション非対応の環境では恩恵を受けられない点に注意が必要だ。また自然言語でのデータ探索(会話型分析)にも対応しており、ML専門知識を持たないビジネスユーザーが直接Icebergテーブルに質問できる導線も同時に提供される。
読者視点での実務的な意味は、BI目的でデータをDWHに複製する運用の見直しが現実的な選択肢に入ったことだ。S3 Tablesを既に採用している組織は、QuickSight Enterprise契約の範囲内で追加のクエリエンジン費用なしに可視化まで到達できる。一方で、既存のAthena経由のダッシュボードやETL前提の基盤をいきなり置き換える話ではなく、新規ダッシュボードや鮮度要件の強い画面から段階的に切り替え、SPICEとDirect Queryのコスト・応答時間を実測して判断するのが妥当だ。