LLMによる強化学習の報酬関数自動生成は、EurekaなどでロボティクスやゲームAIに広がってきた。しかし生成された報酬がそのまま信頼できる学習目標になるとは限らず、学習が不安定化する問題が実務で顕在化している。これまでの研究は「どう生成・進化・選択するか」に焦点が当たっていた一方、「いつ検証し、いつポリシー最適化に投入するか」というデプロイ時の問いは手薄だった。
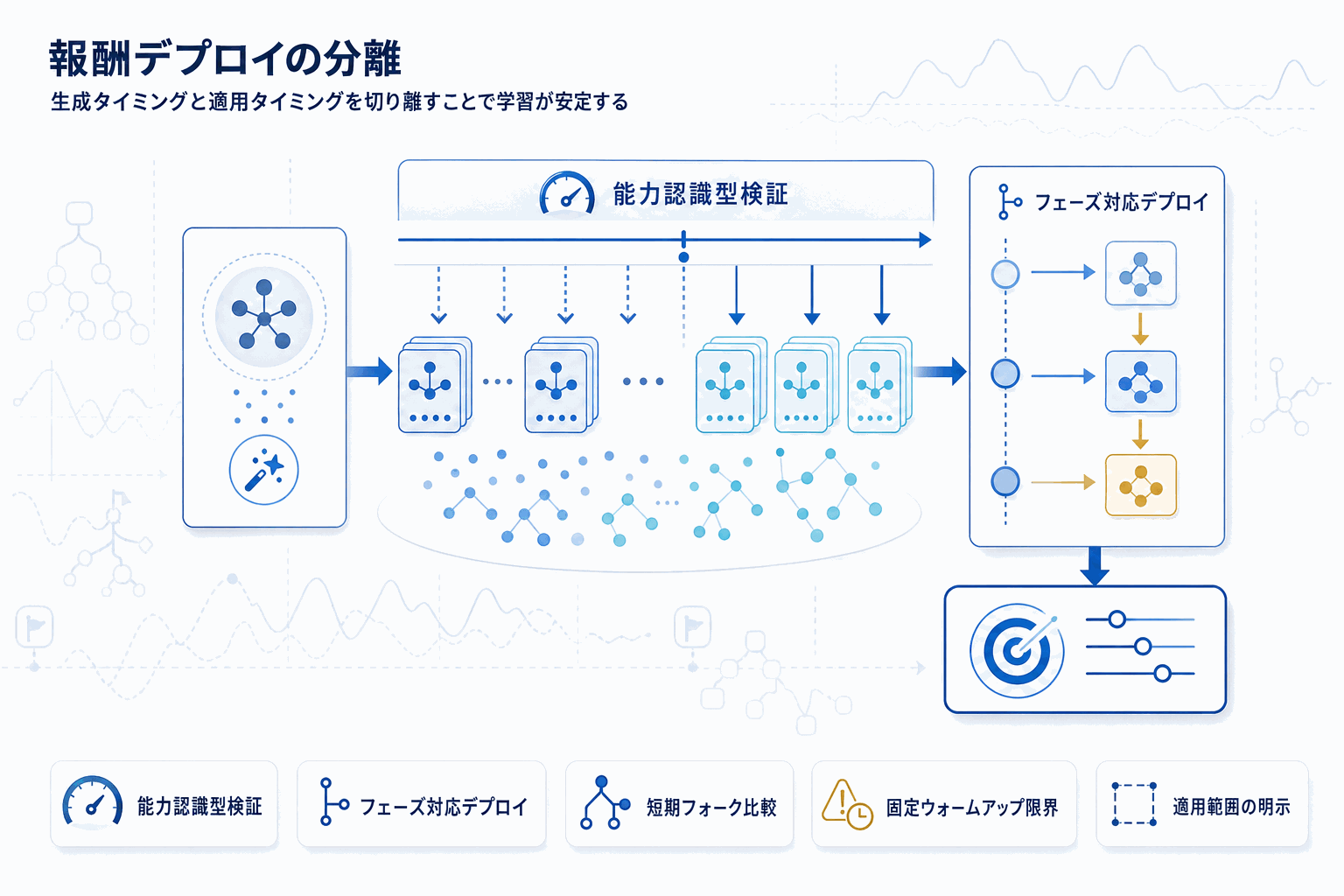
RHyVEはこのデプロイ時問題に正面から取り組む。生成された報酬を「報酬仮説」として扱い、現在のポリシーの能力と学習フェーズに応じて有用性が変わると定式化。共有ポリシーチェックポイントから少数の報酬仮説を短期フォーク検証で比較する、能力認識型検証・フェーズ対応デプロイのプロトコルを提案している。
実験結果のポイントは三つある。第一に、報酬ランキングはポリシー能力が低い段階では信頼できず、タスク依存の閾値を超えてはじめて有意になる。第二に、スパース操作タスクでフェーズ対応デプロイがロックドプロトコル下のピーク性能と保持性能を改善した。第三に、LLM生成報酬プールは候補ファミリー依存でフェーズ依存の勝者交代を示し、固定ウォームアップスケジュールは普遍的に最適ではない。
重要なのは、著者らがRHyVEを汎用スケジューラではなく「検証情報に基づくデプロイプロトコル」と位置づけている点だ。保留スケジュール選択、保守的セレクタ、計算量マッチ対照、スケール対照での検証に加え、密報酬や全失敗境界の実験で適用範囲の限界も明示している。日本の開発現場では、LLM報酬設計を採用するチームにとって、報酬生成と報酬デプロイを結合問題として扱う運用設計の参照点になる。