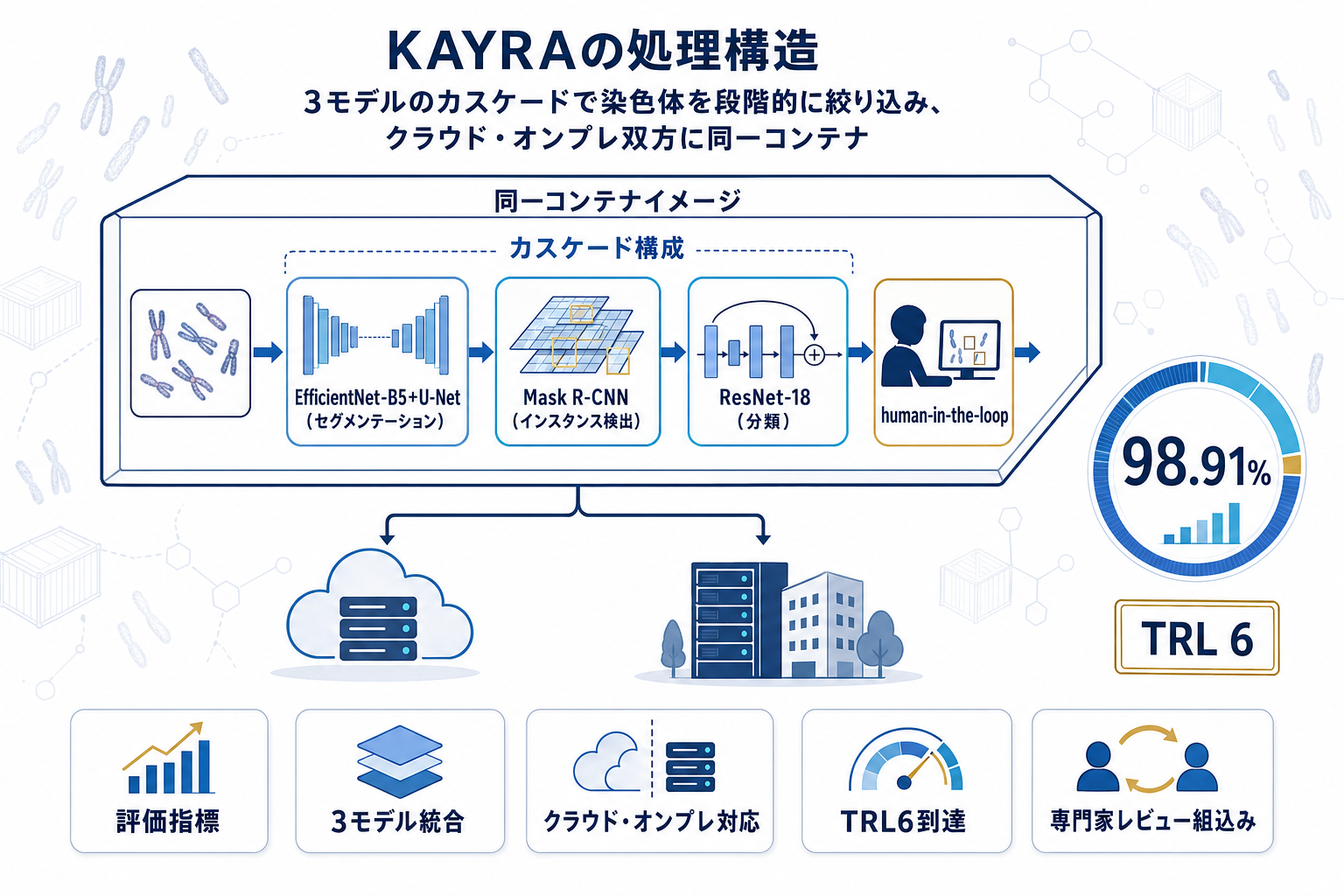
KAYRAは細胞遺伝学ラボの運用制約下で動作するエンドツーエンドの染色体核型解析システムである。機械学習スタックはEfficientNet-B5とU-Netによるセマンティックセグメンタ、ResNet-50とFPNを用いたMask R-CNNのインスタンス検出器、そしてResNet-18の分類器を組み合わせ、ROIを段階的に絞り込むカスケード戦略で染色体領域に下流モデルを集中させる設計を採る。
特筆すべきは同一コンテナイメージをクラウドサービスとしてもオンプレミス設置としても展開できる点である。患者データの院外送出が許されない臨床環境と、許される環境の双方に対応する。日本の多くの医療機関が直面するデータガバナンス制約に対し、アーキテクチャ側で応える実装パターンとして参考になる。
10メタフェーズ・459染色体を用いた商用リファレンス2製品との比較評価では、セグメンテーション精度98.91%(対比78.21%・40.52%)、分類精度89.1%(対比86.9%・54.5%)、回転精度89.76%(対比94.55%・78.43%)を記録。旧世代の密度閾値系リファレンスに対して3軸すべてでFisher正確検定によりp<0.0001、現代AI支援リファレンスに対してもセグメンテーションでp<0.0001の有意差を示した。ただし分類精度については現時点のテストセット規模ではp=0.34で統計的有意差は確認されていない。
システムはTRL 6成熟度に到達しており、診断細胞遺伝実務が要求するhuman-in-the-loopの専門家レビュー工程を統合している。単一の精度競争ではなく、臨床運用制約を満たした配布形態と人間関与工程を含めたパッケージ化が本研究の主張である。