拡散型大規模言語モデル(dLLM)は、自己回帰モデルと異なり双方向文脈と並列デコードを扱えるという構造的利点を持つ。しかし最先端のdLLMは競争力を得るために数十億パラメータを要し、実用展開のコスト障壁が残されていた。既存のdLLM蒸留手法は同一アーキテクチャ内で推論ステップを削減するものに限られ、教師と学生でアーキテクチャ・アテンション機構・トークナイザーが異なる『クロスアーキテクチャ知識転移』は未解決のままだった。
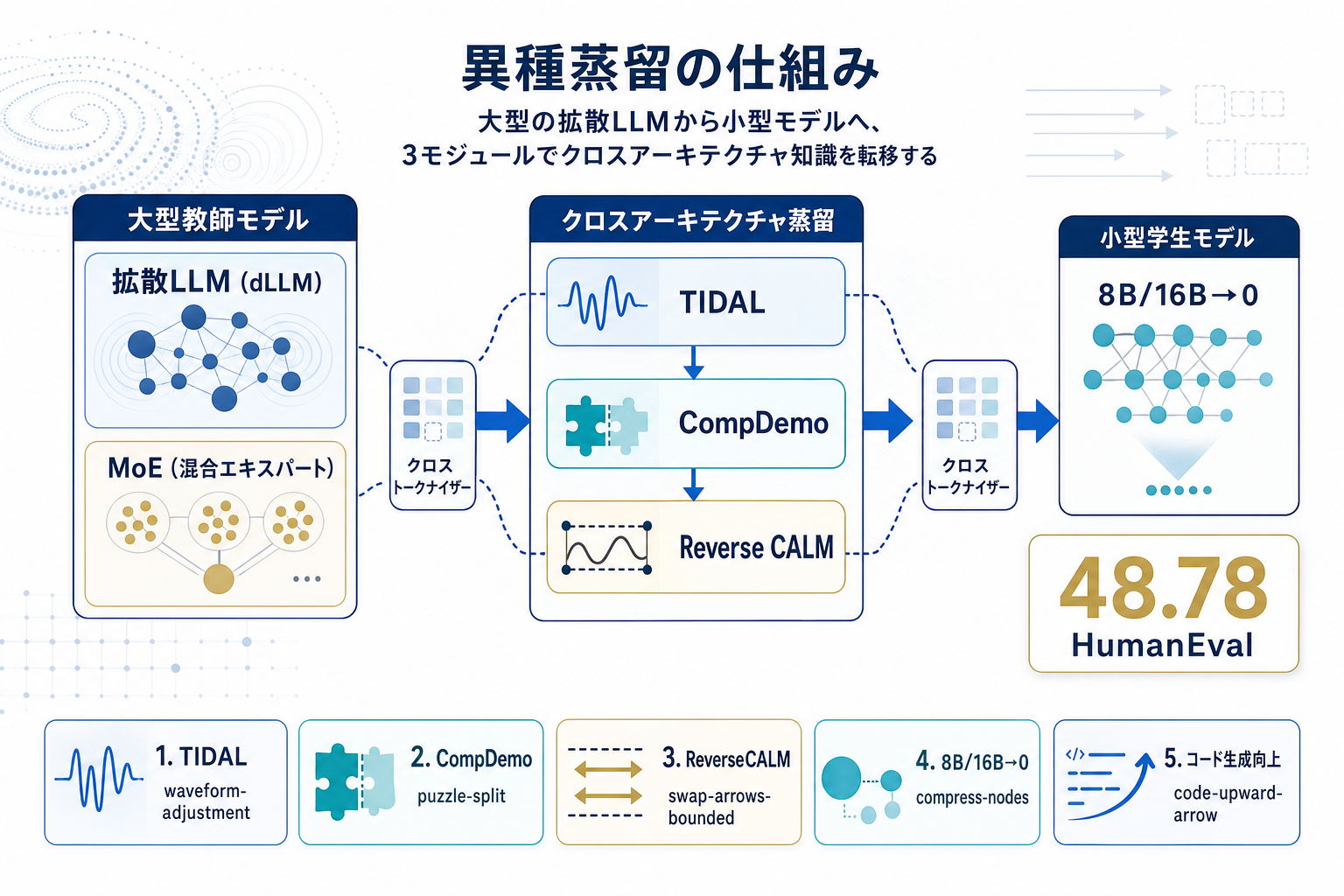
TIDEはこの領域に最初の実装解を提示する。構成は3モジュール。TIDALは訓練進捗と拡散タイムステップに応じて蒸留強度を変調し、教師のノイズ依存信頼性を補正する。CompDemoは補完的マスク分割により教師の文脈を豊かにし、重いマスキング下での予測精度を改善する。Reverse CALMはチャンクレベルの尤度マッチングを反転させたクロストークナイザー目的関数で、勾配を有界に保ち両端ノイズをフィルタリングする。
実証では8B密結合モデルと16B MoEモデルを教師に、0.6B学生モデルへ2系統の異種パイプラインで蒸留。8ベンチマーク平均で1.53ポイント向上し、HumanEvalでは自己回帰ベースライン32.3に対し48.78を記録した。特にコード生成での大幅改善は、軽量な開発支援ツールへの応用経路として具体的な数値根拠を与える。
実装コードはGitHub(PKU-YuanGroup/TIDE)で公開されており、日本の開発現場でも社内検証や再現実験が可能な段階にある。dLLMを商用展開する場合の小型化レシピとして、今後の追随研究の参照点になる。