「Select to Think (S2T)」は、SLM(小型言語モデル)の推論能力をLLMに依存せず高める手法として提案された。従来、SLMとLLMの性能差を埋めるには、推論の分岐点でLLMを呼び出してトークンを生成させる方式か、LLMの生成分布をSLMに模倣させる標準的な蒸留が主流だった。前者は外部API呼び出しによるレイテンシとコストを招き、後者はSLMの容量制約で精度が頭打ちになる課題があった。
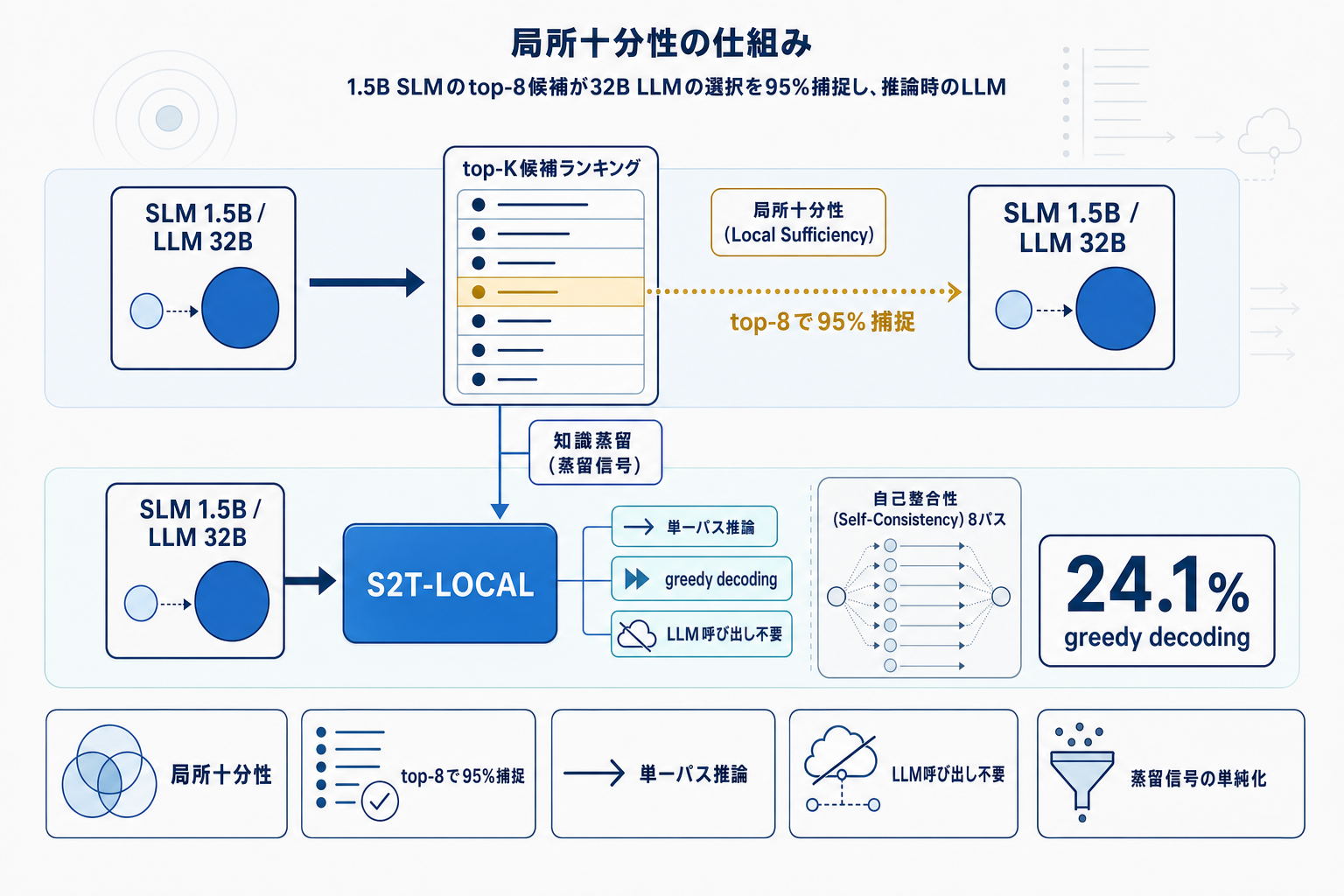
論文の核心は「局所十分性(local sufficiency)」の発見にある。推論の分岐点において、LLMが最終的に選ぶトークンは、SLMがtop-1で選べなくとも、SLMのtop-K予測内に高確率で含まれている。具体的には1.5BのSLMのtop-8候補が、32B LLMの選択を95%の確率で捕捉する。この事実は、LLMの役割を「開放的な生成」から「SLMが出した候補へのランキング付け」へと再定義する根拠になる。
この再定義により、蒸留の監督信号は連続的な分布模倣から離散的な候補ランキングへと単純化される。S2T-LOCALはこの選択ロジックをSLMに蒸留し、推論時にLLMを呼ばずにSLM自身が再ランキングを行う。結果、複数ベンチマークでgreedy decodingを平均24.1%改善し、8パスの自己整合性(self-consistency)と同等の精度を単一パスで達成した。
実務的な含意は明確である。推論コスト・レイテンシ・外部データ送信の3つの制約を同時に持つエッジ・オンプレ・閉域環境において、SLM単独運用の精度的正当性が定量的に補強された。日本の開発現場でも、オンプレ要件の強い業種でのAI導入判断材料となる。