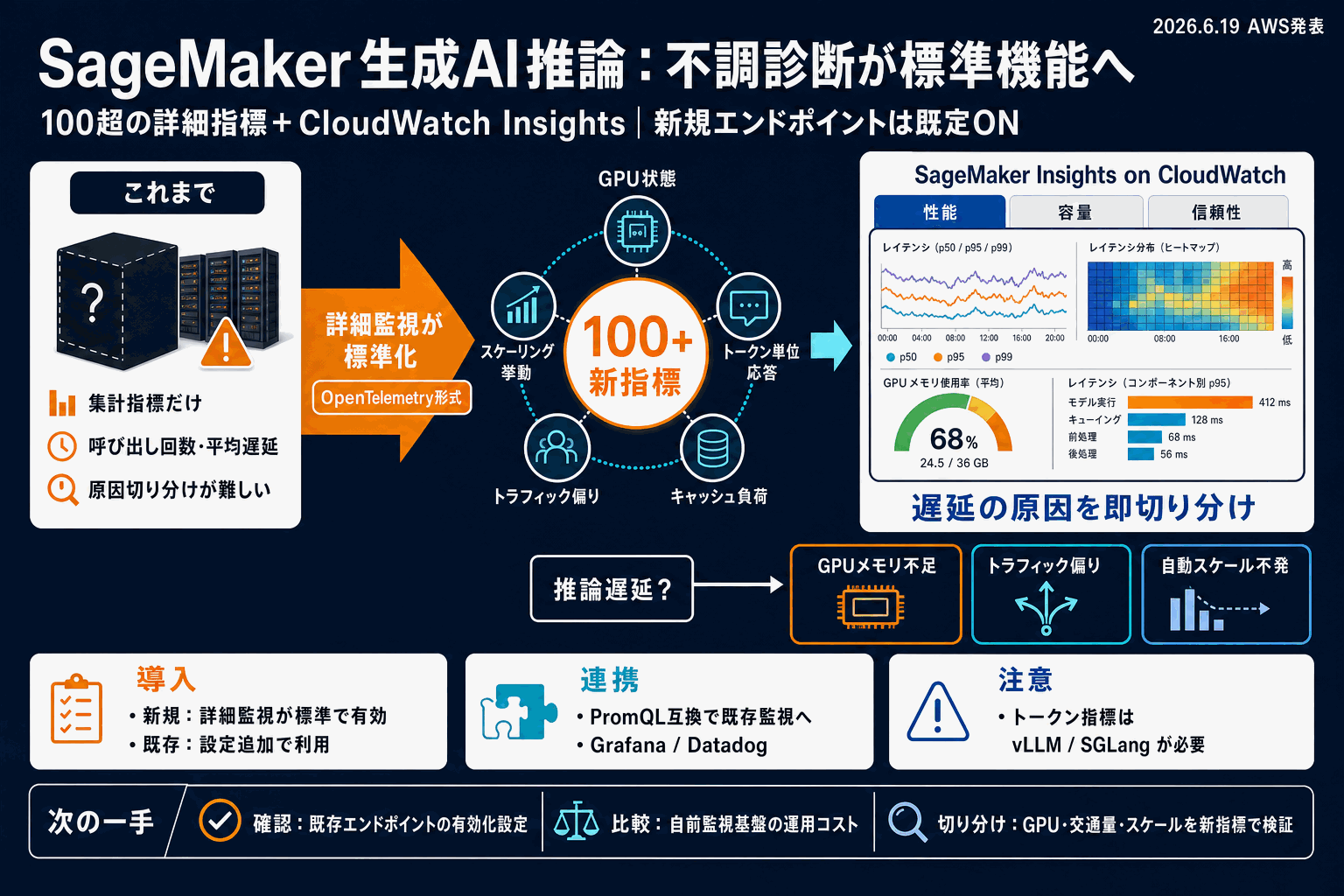
Amazon SageMaker AIが、生成AI推論エンドポイント向けに100種類以上の詳細な監視指標を発信できるようになった。GPUの状態、トークン単位の応答時間、キャッシュ負荷、複数の地域にまたがるトラフィック分散などが対象で、CloudWatch上の専用ダッシュボード「SageMaker Insights」に集約される。ダッシュボードは性能・容量・信頼性の3つの観点で表示され、複数モデルを共有GPU上で動かす構成にも対応する。
背景には、LLM運用で推論段階が運用負荷の中心になり、従来の呼び出し回数や遅延の集計指標だけでは、数十モデルと数百GPUを抱える本番運用に粒度が足りなかった事情がある。これまで詳細な可視化には独自のGrafanaやPrometheusの構築が必要だった。
今回の指標はオープン標準のOpenTelemetry形式でCloudWatchに送られ、PromQL互換クエリで外部ツールに連携できる。新規エンドポイントは詳細監視が既定で有効、既存環境は設定追加で対応する。トークン単位の指標取得にはvLLMまたはSGLangが必要となる。