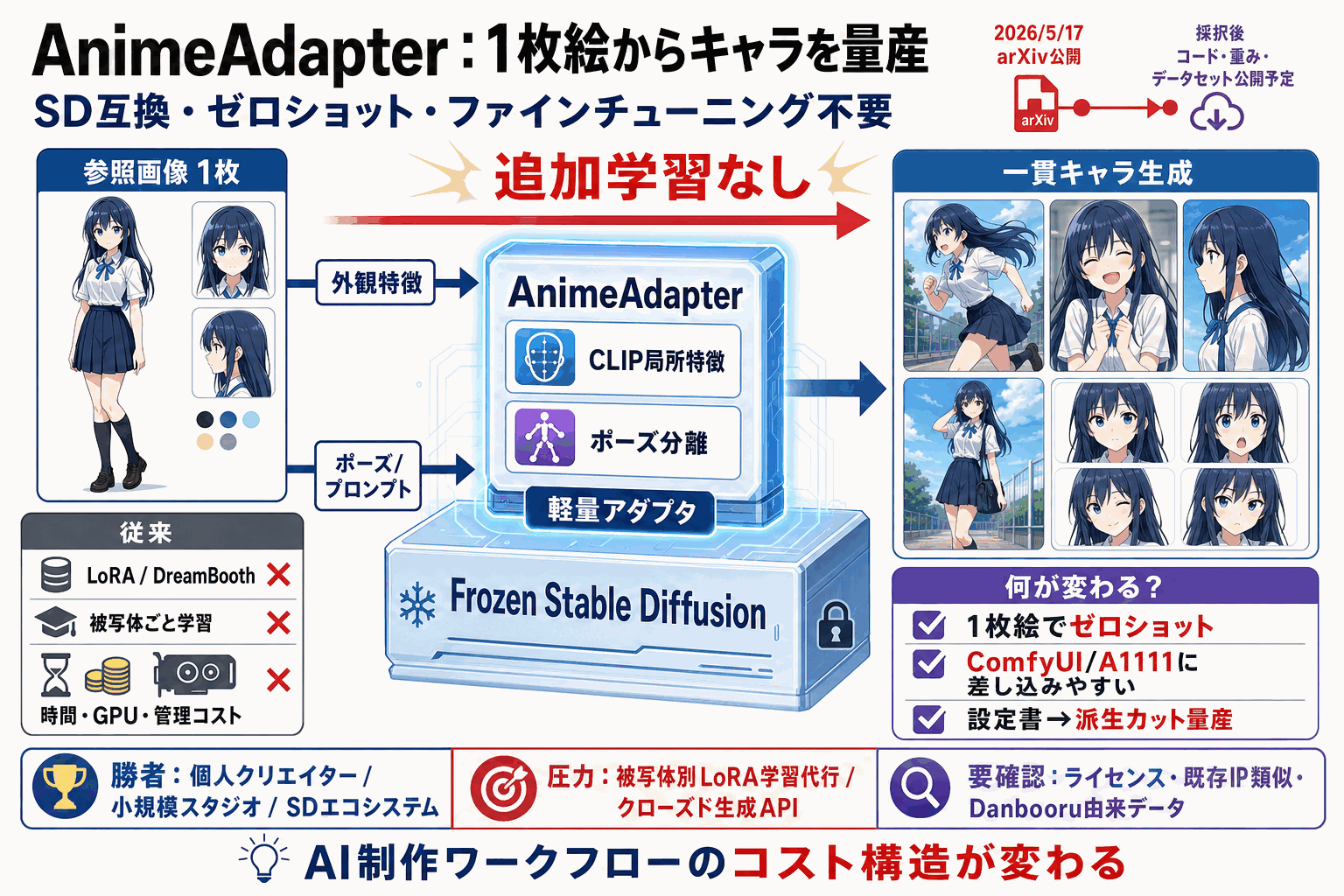
何が新しいのか
AnimeAdapterは、Stable Diffusion向けの軽量な「外観アダプタ」として提案された手法である。大規模ビジョン言語モデルや被写体ごとのファインチューニングに頼らず、1枚の参照画像から細粒度の視覚特徴を抽出して拡散プロセスへ注入する。鍵となるのは、CLIPの創発的な局所空間化(emergent local spatialization)に基づくセマンティック選択的ローカルアテンションで、髪型・衣装・装飾といった意味単位の特徴を必要な領域へ選択的に届ける設計である。
さらにポーズ認識コンディショニングをアダプタ学習時に組み込み、キャラの「外観」と「ポーズ・空間レイアウト」を分離している。これにより、同一キャラを異なるポーズや構図で描き分けても外観の一貫性が崩れにくい。
日本の制作現場への含意
出来上がったアダプタはコンパクトかつモジュール型で、Stable Diffusionコミュニティのワークフローと完全互換、デプロイ時の追加ファインチューニングも不要とされる。これは、ComfyUIやWeb UIベースで運用している国内の個人クリエイターや小規模スタジオが、既存ノードグラフへ差し込みやすいことを意味する。キャラ設定書1枚から派生カットや表情差分を量産する、というアニメ・ゲーム制作の典型工程に直結する。
一方で、データセットはDanbooruプロンプトを精査・再構成した高品質アニメキャラデータセットを構築・公開予定とされており、出自に由来するライセンスとIP類似性の扱いは商用導入前に社内ルールで切り分ける必要がある。コード・モデル重み・データセットは採択後の公開予定であり、現時点では論文ベースで仕様を確認し、公開後に既存のIP-Adapter系やLoRA運用との比較検証へ進むのが現実的な順序である。