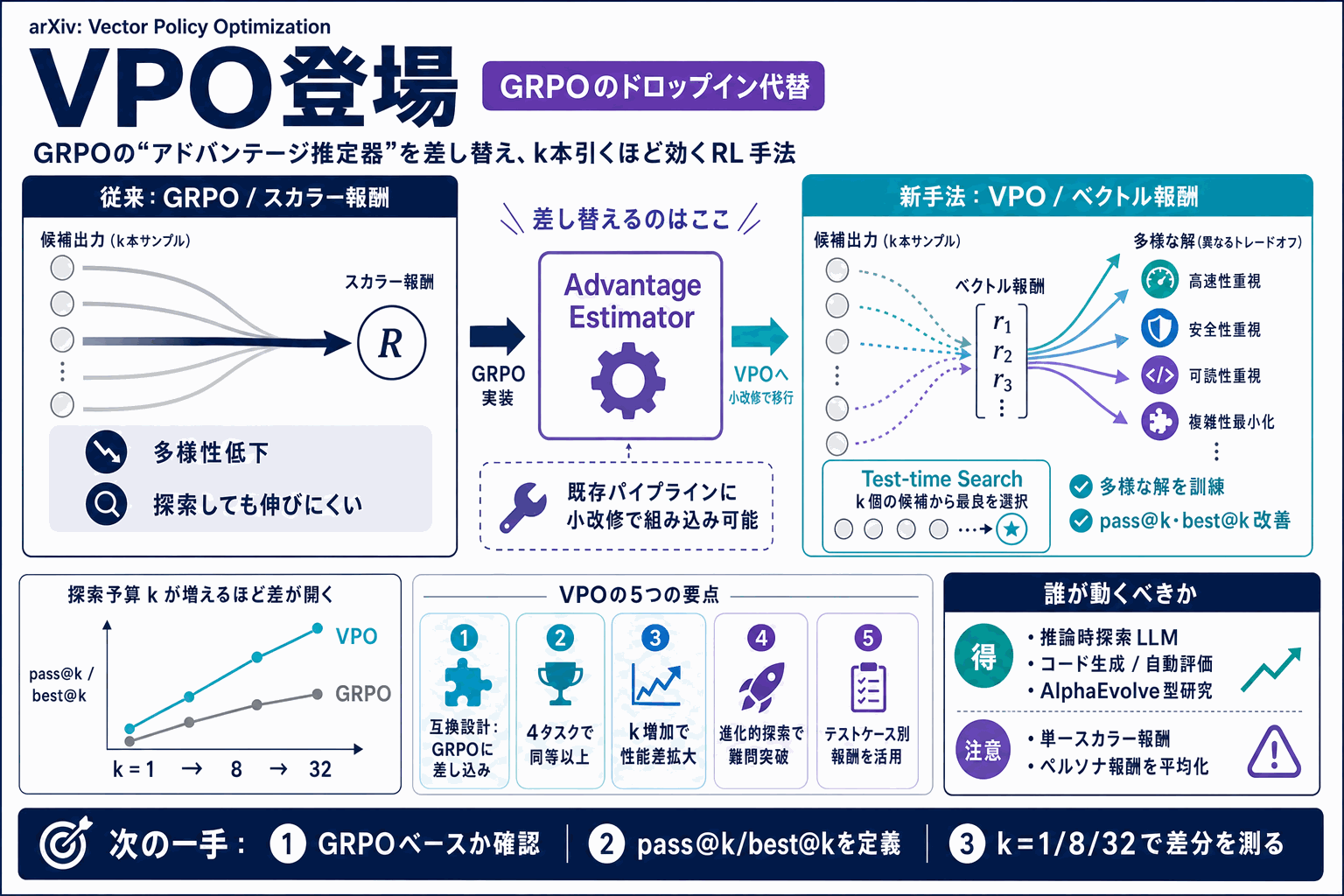
VPOが解こうとしている問題
LLMのpost-trainingは、事前に定めたスカラー報酬の最大化を行うのが標準だった。この設計は単一指標では強いモデルを作る一方、応答分布のエントロピーが下がりやすく、AlphaEvolveのようにロールアウトを多数引いてタスク別報酬で選別する推論時探索の枠組みでは、引いた候補が似通って探索が進まないという問題が顕在化していた。VPO(Vector Policy Optimization)は、この「訓練時に多様性を作り込まない」ことが推論時探索のボトルネックになっているという立場から設計された手法である。
設計と報告された結果
VPOの中核は、報酬を単一スカラーではなくベクトルとして扱う点にある。論文ではコード生成のテストケースごとの正誤判定や、複数の異なるユーザーペルソナ・複数の報酬モデルがベクトル報酬の具体例として挙げられている。VPOはGRPOのアドバンテージ推定器のドロップイン代替として実装されており、出力する解集合の中で個々の解がベクトル報酬空間の異なるトレードオフに特化するよう訓練される。
VPO matches or beats the strongest scalar RL baselines on test-time search (e.g. pass@k and best@k), with the gap widening as the search budget grows. For evolutionary search, VPO models unlock problems that GRPO models cannot solve at all.
4タスクでpass@kとbest@kにおいて最強のスカラーRLベースラインと同等以上、探索予算が増えるほど差が広がる、進化的探索ではGRPOが全く解けない問題をVPOが解いた、という3点が報告された結果の柱である。論文は「テスト時探索が標準化していくにつれ、多様性の最適化がpost-trainingの既定目的になり得る」と主張しており、推論計算を増やす方向に舵を切るチームにとって、訓練側の前提を見直す材料となる。