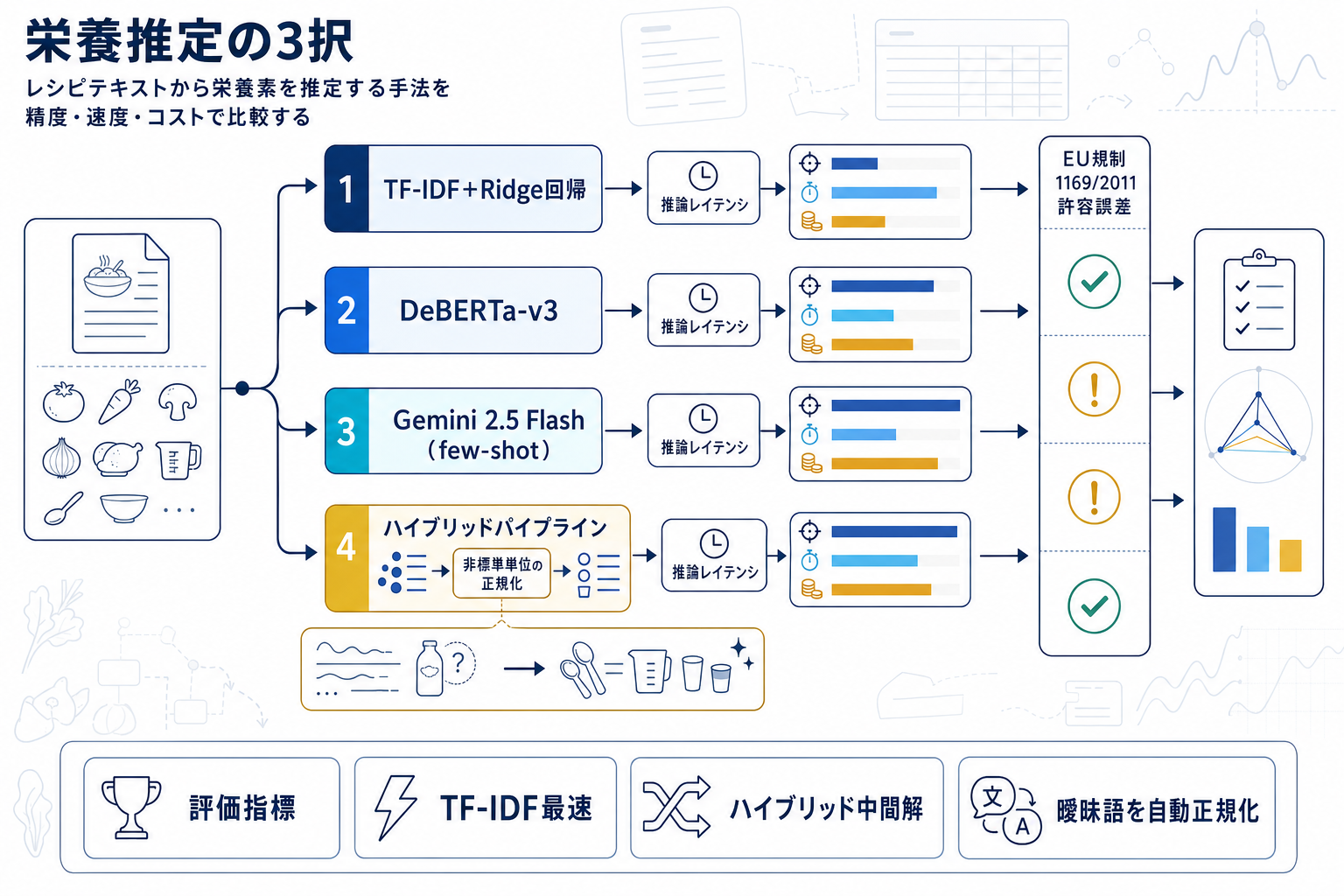
CGU-ILALabがFoodBench-QA 2026向けに発表した本研究は、レシピテキストという非構造化データから栄養素を推定するタスクで、表現能力の異なる3系統のモデルを体系的に比較した。具体的には、語彙マッチング型のTF-IDF+Ridge回帰、深層意味エンコーダのDeBERTa-v3、そして生成推論型のLLM(Gemini 2.5 Flash)である。
評価基準にはEU規制1169/2011が定める栄養表示の許容誤差を採用しており、単なるベンチマーク精度ではなく実運用で求められる法的基準を指標に据えている点が特徴的だ。結果として、TF-IDFは推論速度が最速だが精度は中程度、DeBERTa-v3はタスク固有データが少ない条件下で性能が低下した。対照的に、Gemini 2.5 Flashによるfew-shot推論と、TF-IDFにLLMを組み合わせたハイブリッドパイプラインが、全栄養素カテゴリで最高精度を達成した。
論文では、LLMの優位性が事前学習知識による曖昧な食材用語の解決と非標準単位の正規化に起因すると考察されている。「大さじ1」「少々」のような表現を数値化する工程は、従来の語彙ベース手法では困難な部分であった。
ただし精度向上の代償として、LLMは推論レイテンシが大幅に増加する。食事記録アプリのようにユーザーが食材を入力してすぐ結果を返すリアルタイム用途では、この遅延が実装判断に直接影響する。ハイブリッド構成は、TF-IDFで粗い推定を高速に行い、LLMで精緻化するという役割分担により、精度と速度のバランスを取る実用的な中間解として提示された。