本論文は、Chain-of-Thought(CoT)教師ありの機械学習において、複数の思考者が正しいが体系的に異なる解法を提供する設定を扱う。例として、同じ数学問題に対する異なる人が書いた段階的解答や、同じ問題を解く異なるプログラムの実行トレースが挙げられる。
対象とするのは、単一思考者のCoT教師では計算的に容易に学習できるが、CoTなしの最終結果のみの教師では困難なクラス(Joshi et al. 2025が導入した設定)である。この中間設定で、著者らは2つの対照的な結果を示した。
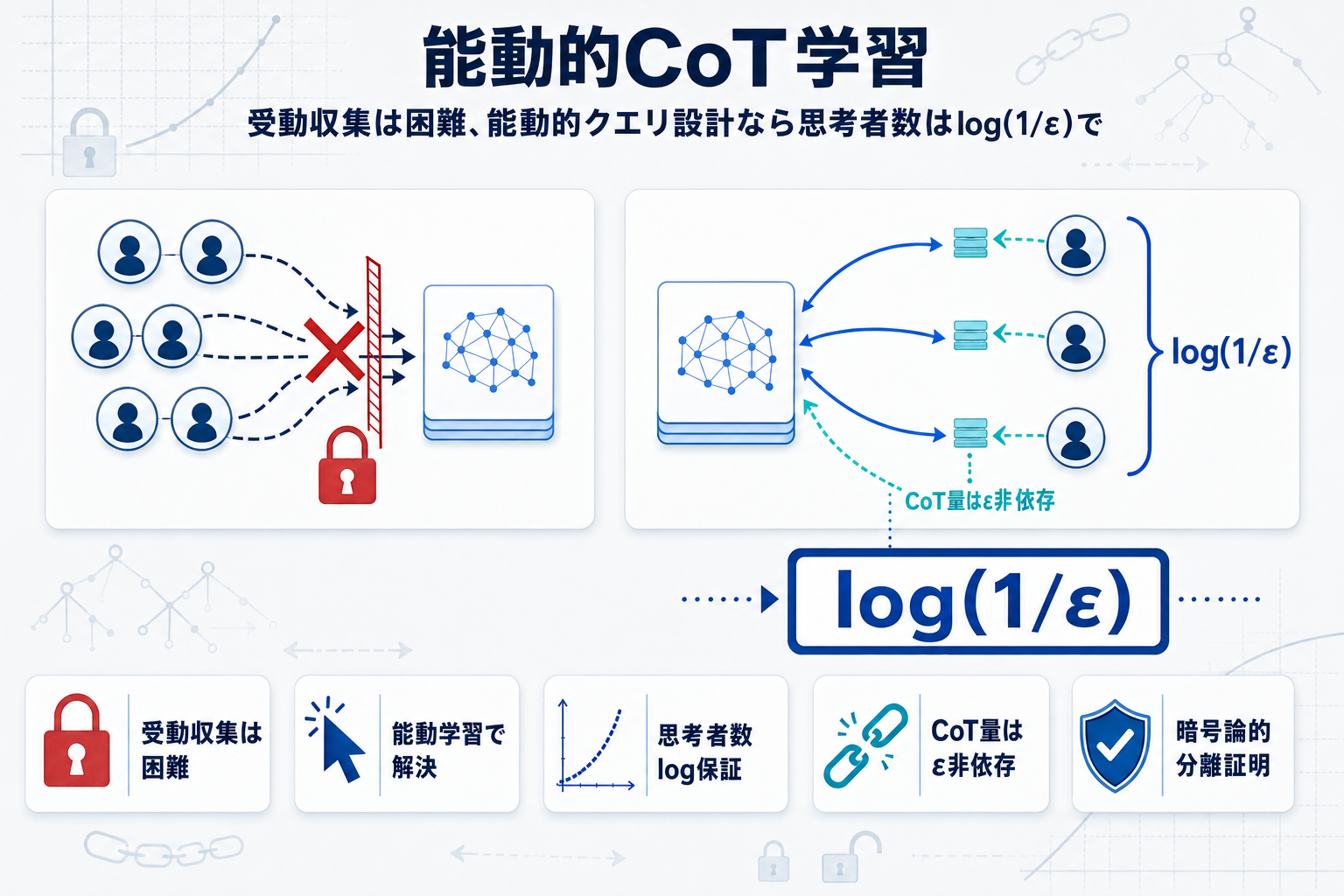
第一に、暗号論的仮定のもとで、受動的データ収集の設定では2人または少数の思考者からのCoT教師でも学習が計算困難となりうる。これは「思考者が混ざるだけでCoTの利点が失われうる」という負の結果である。
第二に、これを克服する計算効率的な能動的学習アルゴリズムを構築した。このアルゴリズムは、各思考者から必要なCoTデータ量がターゲット精度εから完全に独立し、思考者数はlog(1/ε)・log log(1/ε)、受動的な最終結果データは(1/ε)・polylog(1/ε)のスケールで十分である。
この結果は、LLM訓練の実務において「CoTをどう集めるか」という設計判断が、到達可能な精度とコストを本質的に左右することを示している。複数のアノテータや複数の教師モデルからCoTを蒸留する現代的なパイプラインにおいて、受動的に集約するのではなく、能動的なクエリ設計を組み込む理論的根拠を与える成果である。