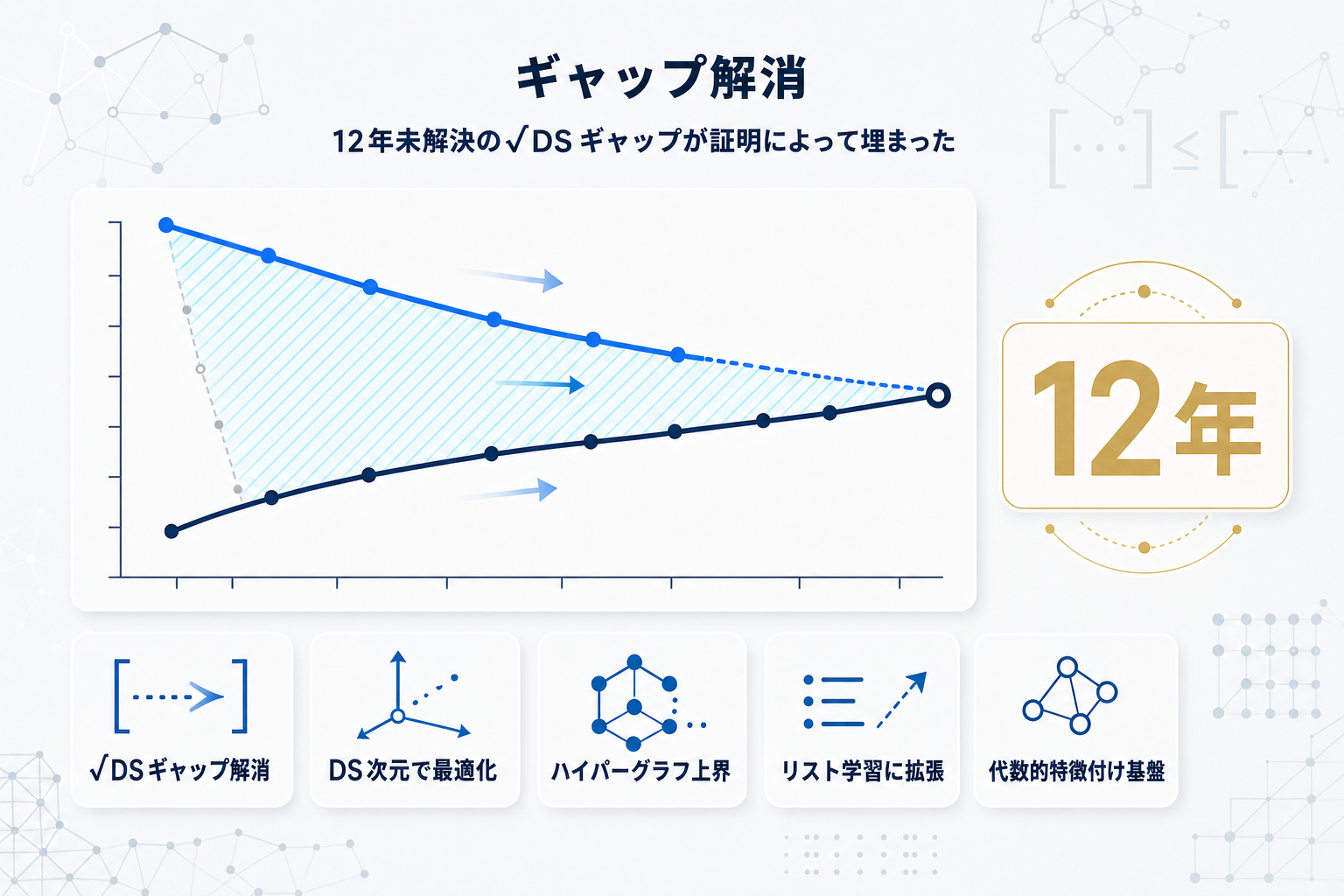
二値分類の最適サンプル複雑度がVC次元で特徴づけられることは古典的に確立されているが、多クラス分類では適切な複雑度パラメータがDS次元であると同定されていたものの、サンプル複雑度の上界と下界の間に√DSのギャップが残っていた。このギャップは2014年にDaniely と Shalev-Shwartzが予想として提示して以来、未解決のまま12年が経過していた。
本論文は、Hanneke ら(2026年)による多クラス仮説クラスのDS次元の代数的特徴付けを土台として、任意の多クラス仮説クラスの最大ハイパーグラフ密度がそのDS次元で上から抑えられることを証明した。この結果として、Daniely と Shalev-Shwartzの予想が肯定的に解決され、多クラス分類とリスト学習の双方について、サンプル複雑度のDS次元への最適依存性が確定した。
実務への直接的なインパクトは限定的だが、多クラス分類は画像認識や自然言語処理の基盤タスクであり、その学習理論的基盤が完結した意義は大きい。今後、DS次元を基準としたアルゴリズム設計や、少数サンプルでの学習効率を議論する際の理論的拠り所として参照されることになる。リスト学習への拡張も同時に示されたため、Top-k予測やマルチラベル寄りの応用領域にも理論的含意が及ぶ。