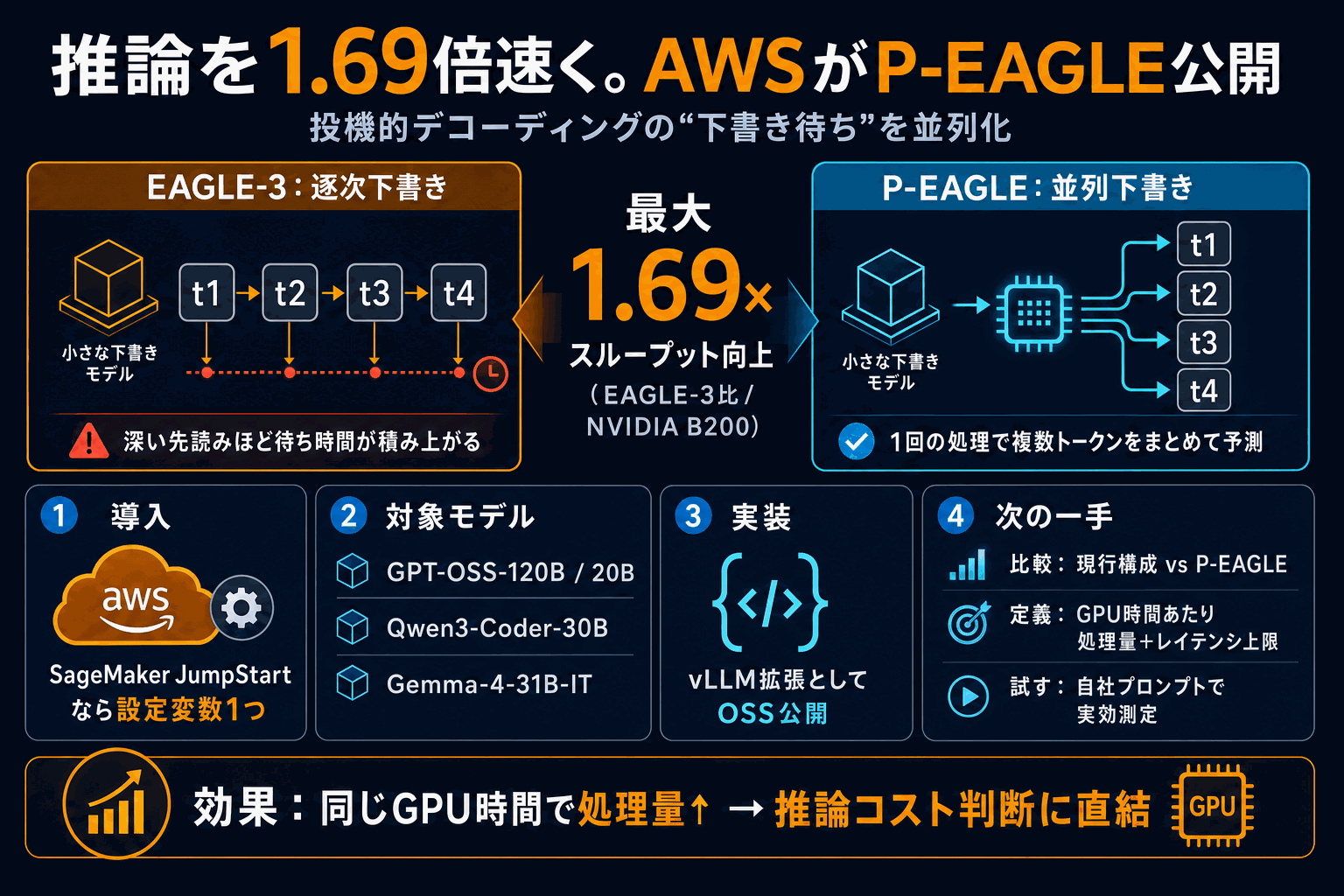
AWSがLLM推論を高速化する新手法P-EAGLE(並列EAGLE)をオープンソースとして公開した。投機的デコーディングは軽量な下書きモデルが次の単語を先読みし、本体モデルがまとめて検証する仕組みだが、代表的枠組みのEAGLEは下書き単語を1つずつ順に生成する構造的限界があった。先読みを深くするほど待ち時間が積み上がり、性能向上を相殺していた。
P-EAGLEは下書き単語を1回の処理でまとめて予測することでこの逐次段階を排除し、先読みの深さと処理回数を切り離す。NVIDIA B200上のベンチマークで、最新版EAGLE-3比 最大1.69倍のスループット向上を達成した。
実装はvLLMの拡張で、Amazon SageMaker JumpStartが標準対応する。GPT-OSS-120B / GPT-OSS-20B / Qwen3-Coder-30B / Gemma-4-31B-ITの4モデルが事前設定済みで、独自コンテナや複雑な並列処理設定を管理せず設定変数(parallel_drafting)で有効化できる。本番運用するエンタープライズの推論コスト判断に直結する手法だ。