Googleは2026年5月20日、Web上のコンテンツがどのように作成・編集されたかを利用者が把握しやすくするためのツール群を拡張すると公式ブログで発表した。AI生成メディアをオンラインで識別する取り組みの延長線上にある施策で、対象範囲をWeb全体へ広げる位置づけとなる。
背景には、生成AIによる画像・動画・テキストの量産が進み、出所不明のコンテンツがソーシャルメディアや検索結果に流通する状況がある。GoogleはこれまでもSynthIDによる電子透かしや、画像検索での「About this image」機能などを段階的に展開してきた。今回の発表はそれらを統合的に拡張する流れに位置する。
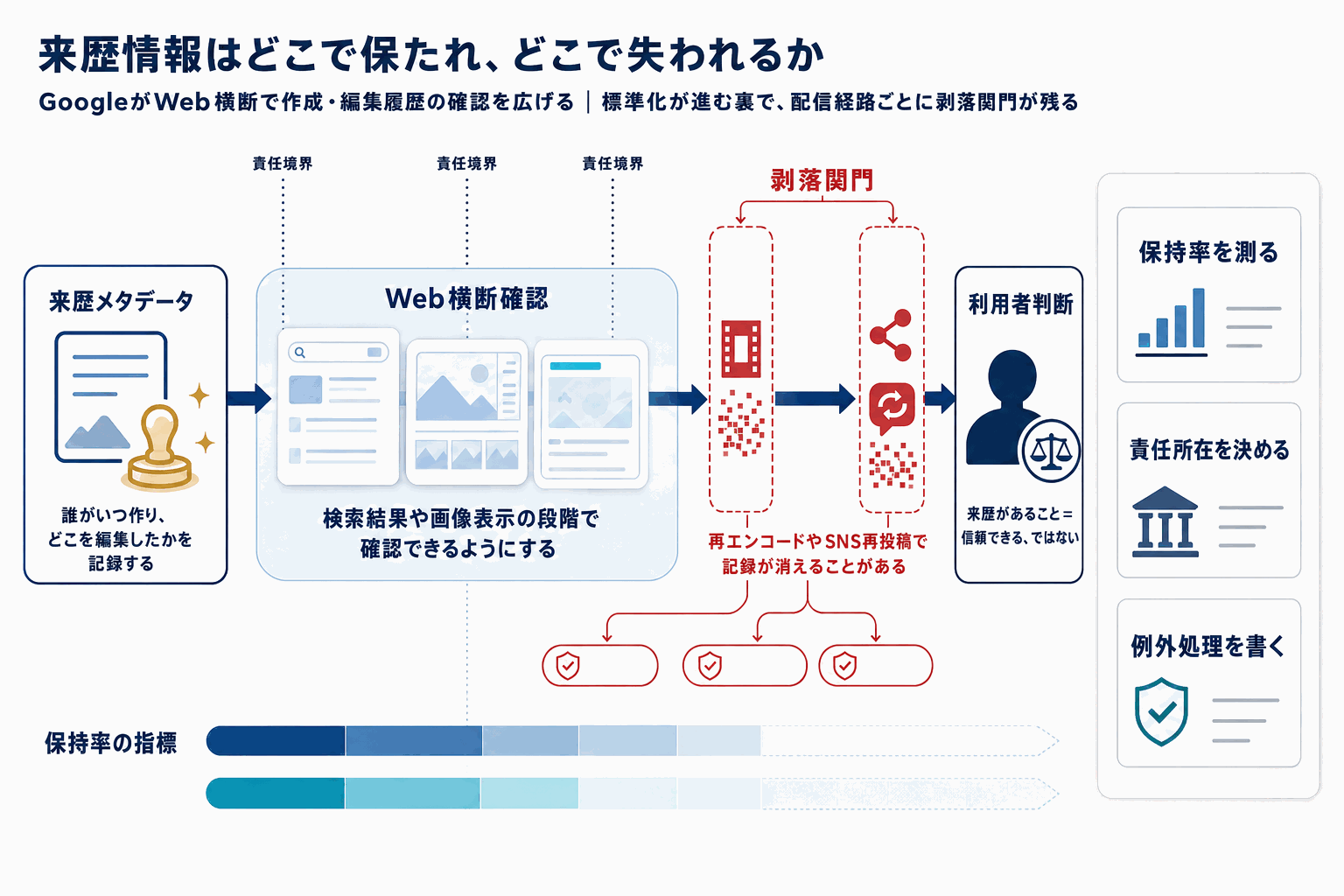
日本の事業者にとっての含意は明確だ。報道機関、出版社、広告主はコンテンツに来歴メタデータを付与するワークフローを整備する必要が出てくる。特にC2PA(Coalition for Content Provenance and Authenticity)規格への対応は、Adobe、Microsoftに続きGoogleが本格対応を進めることで事実上の標準に近づく。
一方、課題も残る。メタデータは編集・再エンコードで剥落しやすく、SNSへの投稿時に保持される保証はない。また、来歴情報の有無が「信頼できるコンテンツ」の判定に直結するわけではなく、利用者側のリテラシーも問われる。
実装担当者は、自社の配信パイプラインで来歴情報がどこまで保持されるかを切り分けて測る作業から始めることになる。事業判断者は、AI生成物の表示ポリシーと来歴付与の運用責任を社内で定義しておく段階に入った。