OpenAIは「Codex for Work」シリーズの一環として、データサイエンスチーム向けのCodex活用手引きをOpenAI Academyに公開した。あわせて開発者ポータル developers.openai.com/codex/use-cases に複数のユースケースが整理され、その中に「Analyze datasets and ship reports(データセット分析とレポート出力)」という独立ページが設けられている。
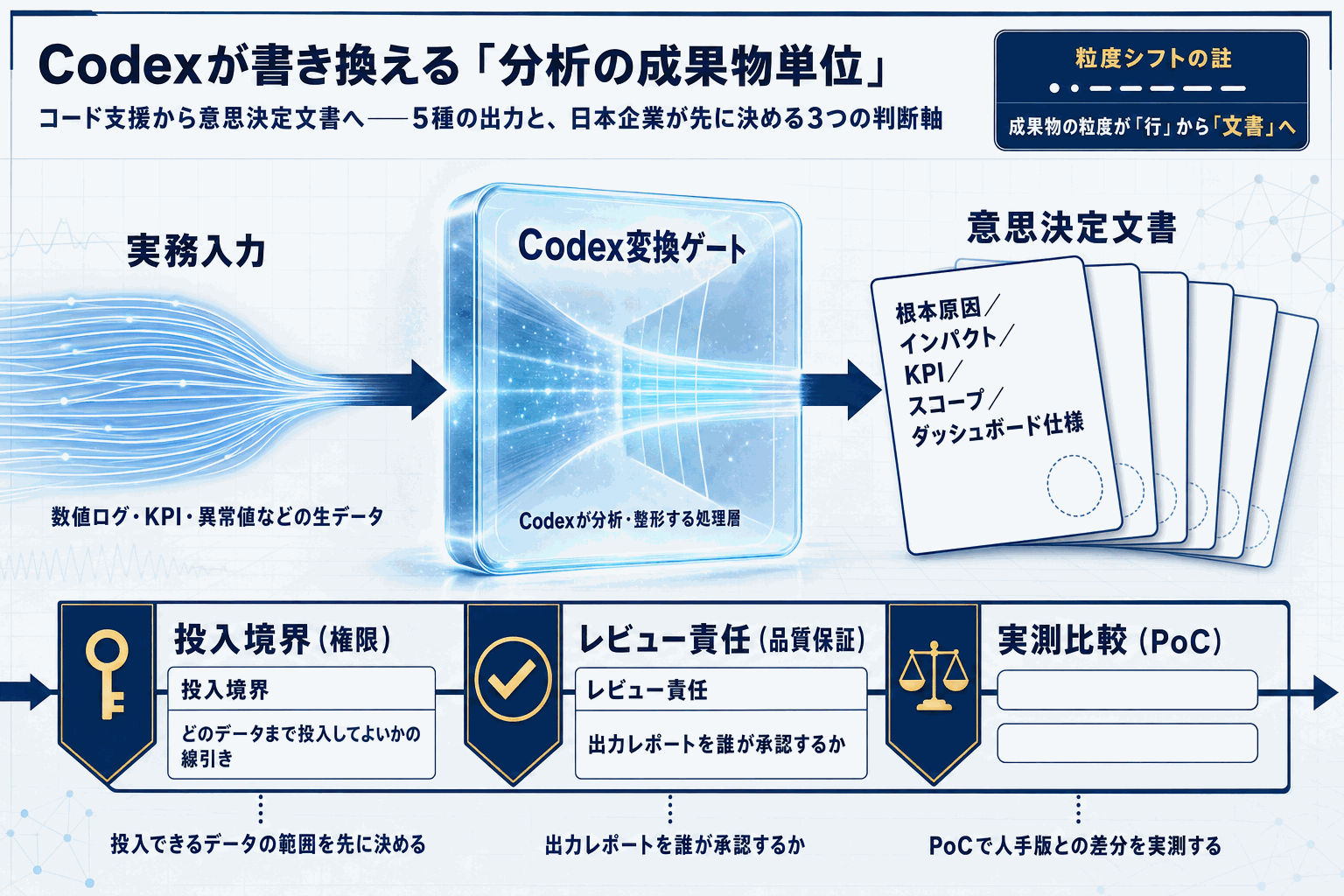
注目すべきは、Codexの訴求軸が「コードを書く支援」から「業務ロール別の成果物を出す支援」に移っている点だ。データサイエンス職にとっての成果物はスクリプトではなくレポートと意思決定材料であり、今回の手引きはその粒度に合わせて整理されている。GitHub Copilotがコード行単位、Cursorがリポジトリ単位で勝負しているのに対し、Codexはタスク単位の訴求で差別化を狙う構図になる。
日本企業の実務観点では、評価ポイントは2つある。第一に、社内データセットをCodexにどこまで投入できるかという権限境界の定義。第二に、生成されたレポートのレビュー体制をどう組むかという品質保証の運用設計だ。本ガイドは具体的な数値ベンチマークを提示していないため、自社の定型分析業務1件で人手版との差分を実測することが、導入判断の最短ルートになる。
なお他社比較の観点では、Anthropic Claude Codeが同様にエージェント型分析を訴求しているため、コスト・出力品質・社内データ接続性の3軸で並行評価することが望ましい。公開された価格・ROI数値はガイド内になく、自社PoCでの実測が前提となる。