本研究は、Doc-to-LoRAに代表されるハイパーネットワーク型のLLM即時適応が抱える構造的な弱点を、定量的に解き明かした点に価値がある。文書を1回の順伝播でモデルの重みに内在化させるこのアプローチは、RAGのような推論時コストを伴わない魅力がある一方、事前学習知識と矛盾する内容の書き換えで体系的に失敗していた。
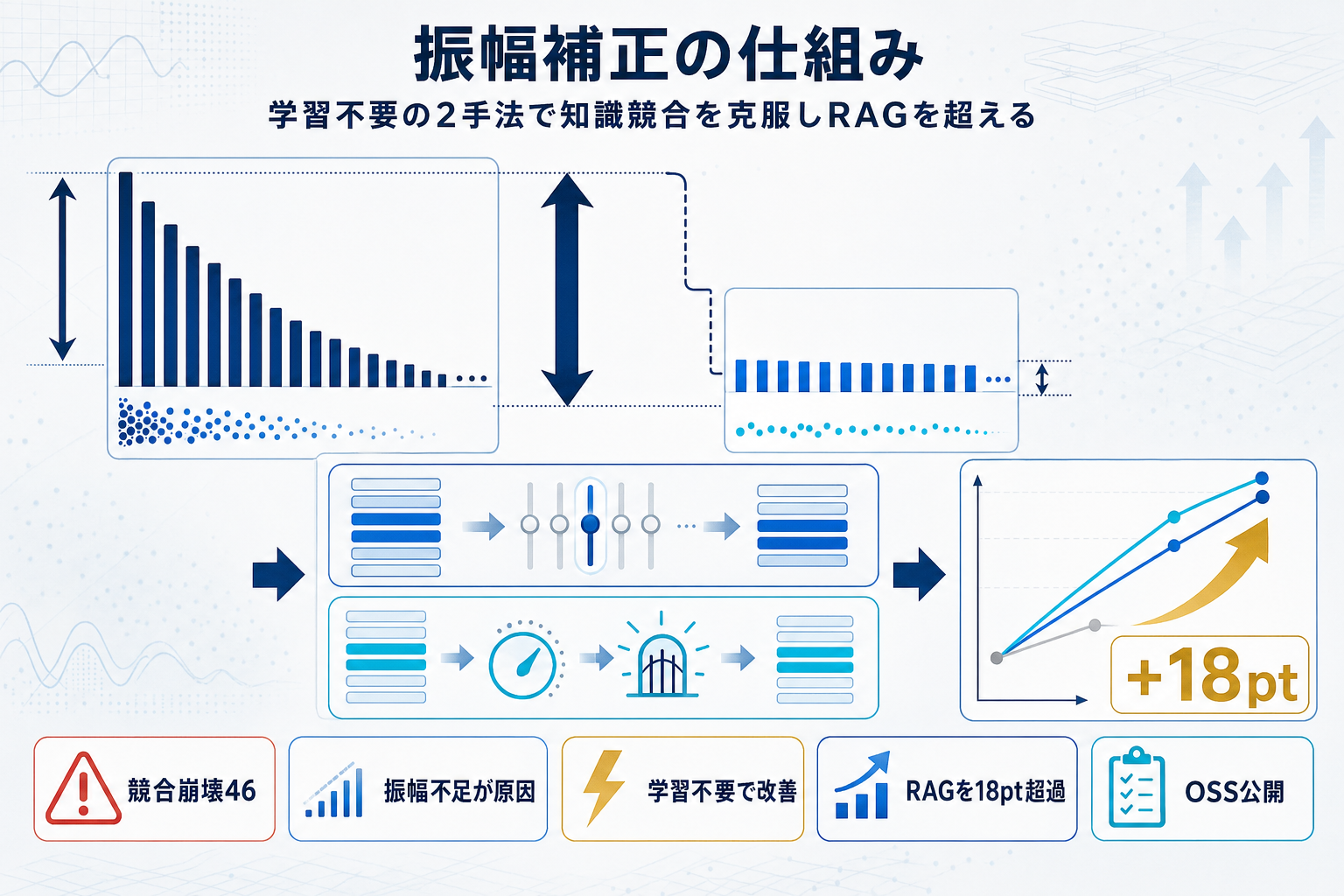
著者らの主張は明快だ。失敗は「表現の問題」ではなく「振幅(マグニチュード)の問題」である。ハイパーネットワークは正しい層を狙っているが、アダプタが生むマージンが文書間でほぼ一定なのに対し、事前学習が持つマージンは学習頻度とともに成長する。そのため、頻出事実を上書きしようとすると構造的に負ける。194件の競合を矛盾事実の対数尤度で並べると、弱prior問題で68%だった正解率が強prior問題では16%まで落ち、52ポイントのギャップが現れた。
処方箋は振幅の増幅である。Selective Layer Boostingはアダプタのトップノルム層だけをスケールし、Conflict-Aware Internalizationはベースモデルが高確信のときだけブーストを発動する。どちらも学習不要で、Gemma-2Bでは46.4%→71.0%、Mistral-7Bでは53.6%→72.5%へと深い競合の精度を押し上げ、しかも新規知識のリコールは維持される。中程度の競合では、素のRAGをパラメータ空間内手法だけで18ポイント上回った。
併せて公開されたKID-Benchは489問からなり、新規リコール、知識の組み合わせ、prior強度別の競合を分離して評価できる。実装者が自社モデルの弱点を層別に診断し、手法選択を数値で根拠づけるための共通尺度として活用できる。