本研究は、AIエージェントが実タスクでどれだけのトークンを消費するかを、8つの最先端LLMのSWE-bench Verified上の実行軌跡から分析した初の体系的研究である。論文はarXivで2026年4月25日に公開された。
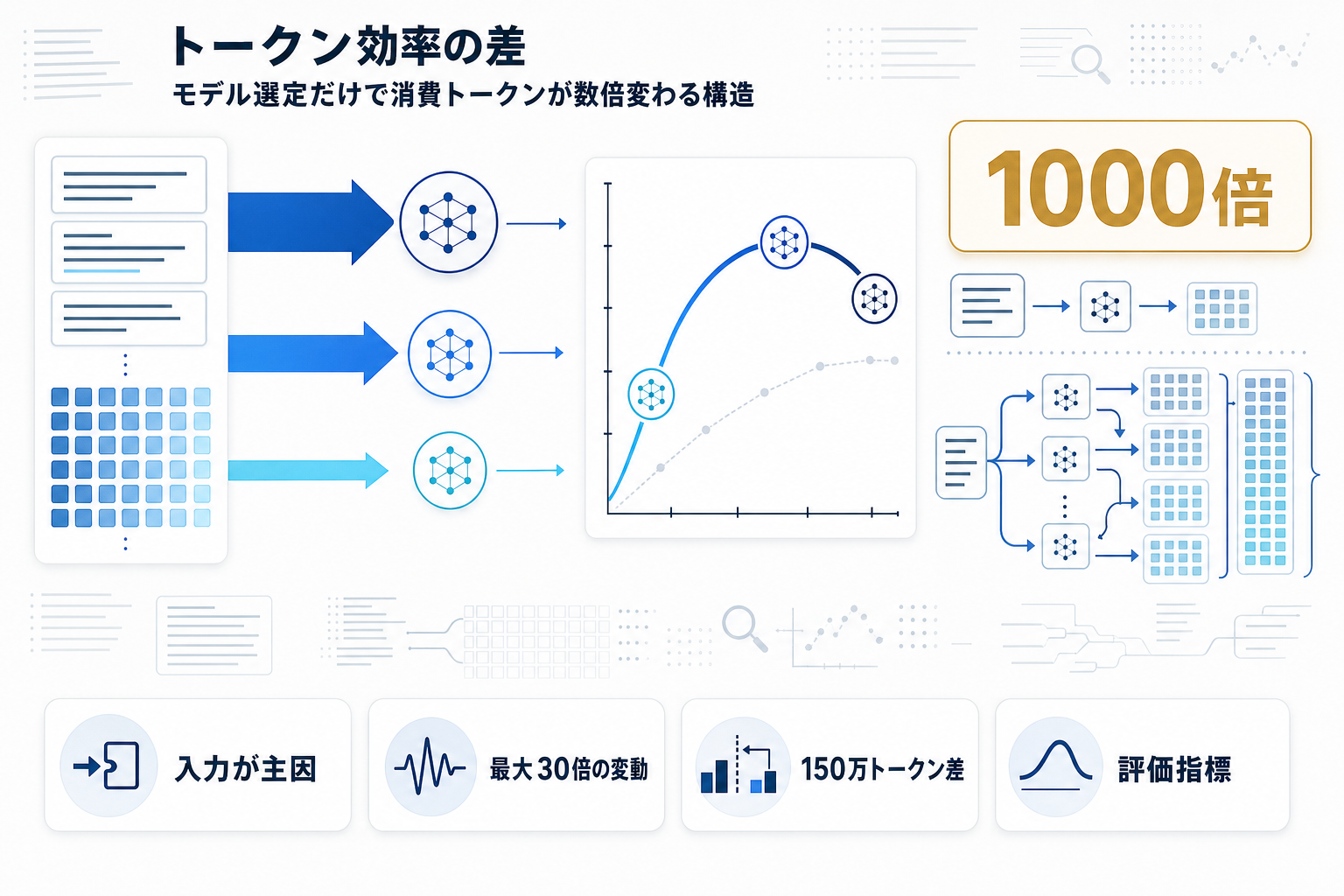
主な発見は5つある。第一に、エージェント型タスクはコード推論やコードチャットと比べて最大1000倍のトークンを消費し、その主因は出力ではなく入力トークンである。プロンプト・ツール応答・過去軌跡の積み上げがコストを支配する構造が定量化された。
第二に、同一タスクの実行でもトークン使用量は最大30倍の差が生じる。さらにトークン使用量が多いほど精度が上がるわけではなく、精度は中程度コストでピークに達し高コスト域で飽和する。「予算を積めば解ける」という素朴な前提が反証された形だ。
第三に、モデル間のトークン効率差は顕著で、Kimi-K2とClaude-Sonnet-4.5はGPT-5と比べて平均150万トークン以上多く消費した。同じタスクでもモデル選定だけで請求額が数倍変わる。
第四に、人間の専門家が評価したタスク難易度と実際のトークンコストは弱い相関しか示さず、人間の体感とエージェントの計算負荷にはギャップがある。
第五に、最先端モデルは自身のトークン消費を相関係数最大0.39でしか予測できず、実コストを系統的に過小評価する。事前見積もりを AI 自身に任せられないことを意味しており、FinOps 的な外部計測が実運用の必須要件となる。