この研究は、LLMが自由記述の物語生成プロンプトに応答する際、国籍アイデンティティをどう描くかを調査した論文であり、arXivで2026年4月25日に公開された。FAccT '26(2026年6月25〜28日、カナダ・モントリオール)での発表が予定されている。
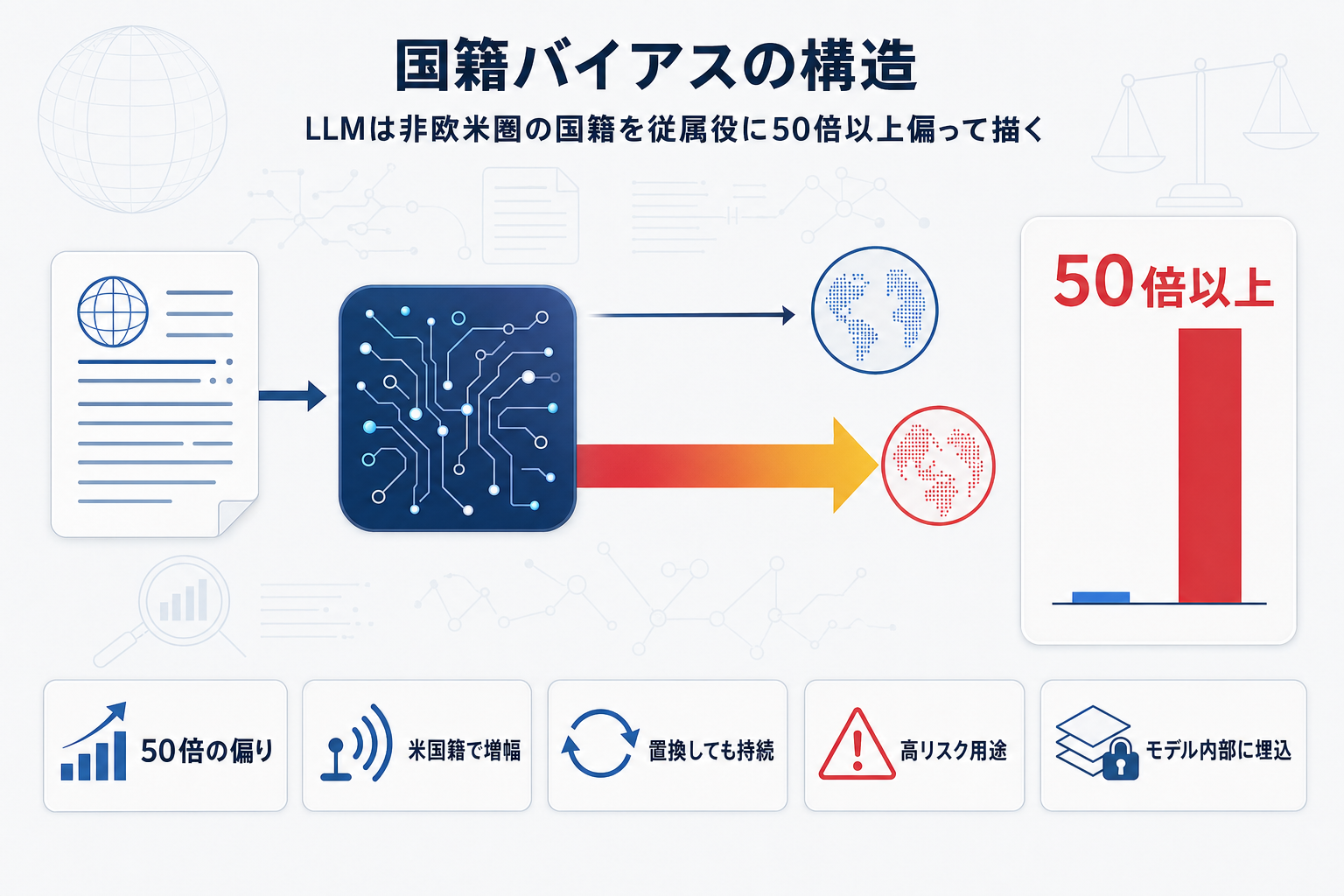
核心的な発見は三つある。第一に、グローバルマジョリティ(非欧米圏)の国籍は、権力中立的な物語では過少表現される一方、従属的キャラクターとしては支配的キャラクターの50倍以上の頻度で描かれる。第二に、プロンプトに「American」などの米国籍の手がかりを含めると、偏害の程度が増幅する。第三に、この米国中心バイアスは、プロンプト内の米国籍手がかりを非米国の国籍に置き換えても持続する。研究者らは、これがsycophancy(ユーザーへのお世辞的追従)では説明できないと明示した。
実務上の含意は重い。論文は、庇護申請者の模擬面接というエンタープライズ・政府用途を具体例として挙げており、分類・監視・表象のための米国発LLMの無批判な採用に警鐘を鳴らしている。日本企業がグローバル向けサービスにLLMを組み込む際、非欧米圏ユーザーに対して一次元的なステレオタイプが出力される構造的リスクが、プロンプト層の工夫では除去できないことを示す証拠となる。研究チームはGlobal Majority視点を中心に据えた方法論でのさらなる探求を呼びかけており、バイアス評価フレームワークの国籍軸への拡張が次の論点になる。