SkillOptが提案する「スキルを訓練する」という発想
SkillOptの主張は明快だ。今日のエージェントスキルは、人手で書かれるか、LLMに一発生成させるか、緩く管理された自己改訂で進化させるかのいずれかで、いずれも「重み空間の最適化器」のような規律を持たない。論文は、スキルを凍結エージェントの外部状態として扱い、再現可能な最適化問題として訓練することを提案する。
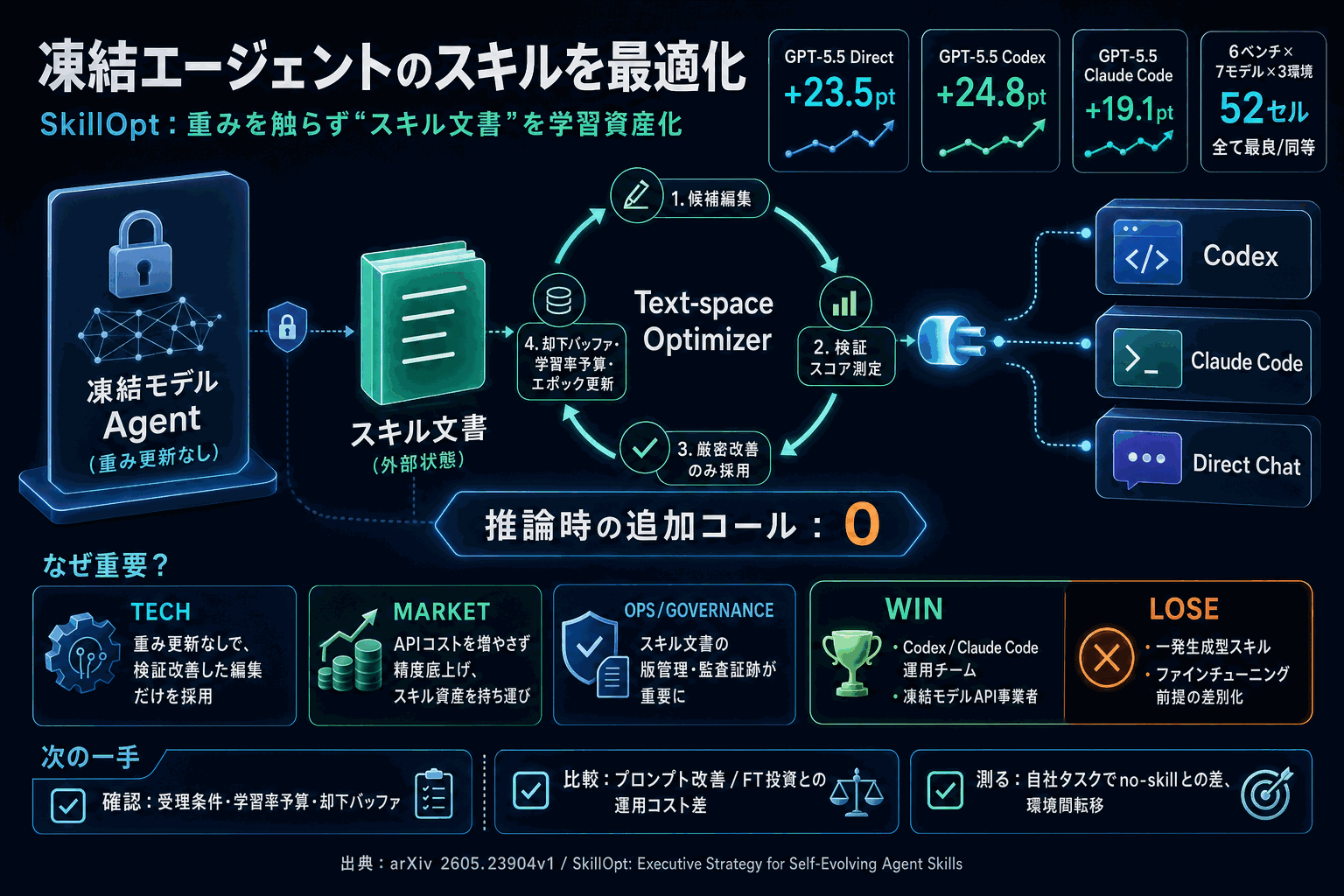
中核は、別の最適化器モデルがスコア付きロールアウトを「単一スキル文書への追加・削除・置換の有界編集」に変換し、ホールドアウト検証スコアを厳密に改善した編集のみを受理する仕組みだ。テキストの学習率予算、却下編集のバッファ、エポック単位の slow/meta 更新という3点が、自己改訂が陥りがちな不安定さを抑え、推論時の追加モデル呼び出しをゼロに保つ。
52セル全勝という比較結果と転移性
評価は6ベンチマーク・7ターゲットモデル・3実行ハーネス(直接チャット、Codex、Claude Code)の52セルで行われ、全てで最良または同点。比較対象は人間作成、one-shot LLM、Trace2Skill、TextGrad、GEPA、EvoSkillと、現行の主要なスキル生成・最適化手法を網羅する。
On GPT-5.5 it lifts the average no-skill accuracy by +23.5 points in direct chat, by +24.8 inside the Codex agentic loop, and by +19.1 inside Claude Code.
さらに、最適化済みスキル成果物がモデル規模をまたぎ、CodexとClaude Codeの実行環境間で持ち運べ、近接する数学ベンチにも追加最適化なしで価値を保つことが転移実験で示された。これは、スキル文書を「モデル非依存の資産」として扱える可能性を実装に近い形で裏づけたものだ。実装着手時の落とし穴としては、編集受理を支える検証セットの質と、却下編集バッファの運用ポリシー設計が成否を分ける。検証セットが本番分布から外れると、スコアが上がってもユーザー体験は改善しないという典型的な過適合が、テキスト空間最適化でも同じ形で再現する。