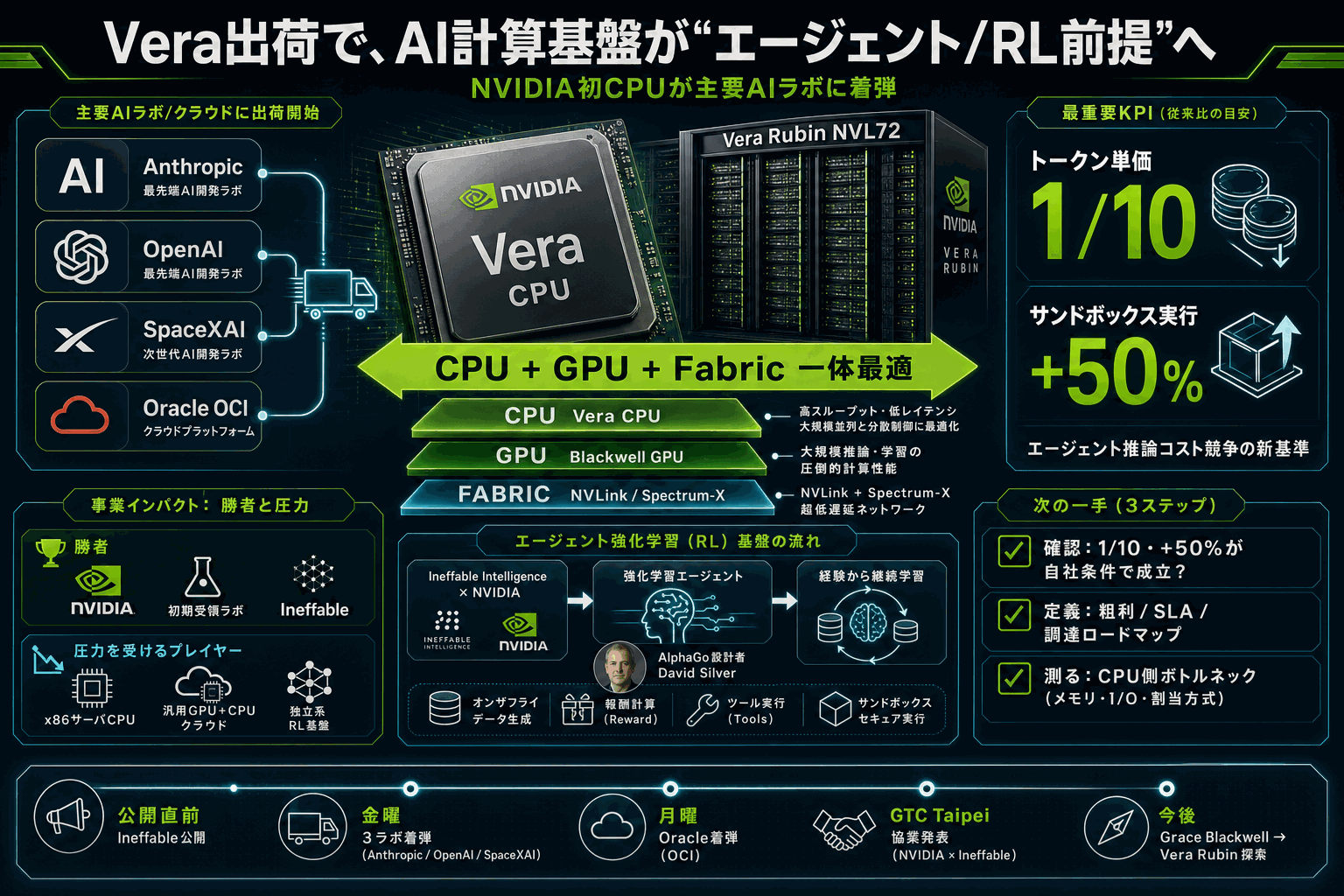
Vera CPUが示す『エージェント前提の計算スタック』
NVIDIA初のCPU Vera は、Anthropic(サンフランシスコ)、OpenAI(Mission Bay)、SpaceXAI(パロアルト)の3ラボへ金曜に、Oracle Cloud Infrastructure(サンタクララ)へ月曜に着弾した。NVIDIA Hyperscale and HPC担当VPの Ian Buck 氏が手渡しで搬送した点は、Vera Rubin NVL72世代の立ち上げをフロンティアラボ4社の運用結果で先に証明する戦略であることを示す。
The first NVIDIA Vera CPUs arrived at three of the world's leading AI labs on Friday — Anthropic in San Francisco, OpenAI in Mission Bay, SpaceXAI in Palo Alto — followed by a delivery to Oracle Cloud Infrastructure in Santa Clara on Monday.
発表ではVera Rubin NVL72との組み合わせでエージェントAI推論のトークン単価が10分の1、エージェントサンドボックス実行速度が従来CPU比で50%向上するとされる。これらは『LLM推論』ではなく『エージェント実行(ツール呼び出し・サンドボックス・状態管理)』を基準に語られている点が重要で、CPU側がエージェントループのボトルネックになっていた現状を、自社CPUで取り戻す宣言に近い。
Ineffable協業が示す『RLは別物』という前提
同時に発表されたのが、AlphaGo設計者 David Silver 氏が創業しステルスから先週公開された Ineffable Intelligence との協業だ。協業はGrace Blackwell上で開始され、次世代Vera Rubinを初期探索する。発表は強化学習エージェントを『試行錯誤で計算を新しい知識に変換するシステム』と定義し、データをオンザフライで生成するRLは事前学習とは異なるインターコネクト・メモリ帯域・サービング要件が生じると明記している。Jensen Huang CEOがRLエージェントを『スーパーラーナー』と呼んだことと合わせ、計算スタックを『事前学習向け』から『継続学習・エージェント向け』に作り替える方針が、Vera CPUとIneffable協業の両輪で示された格好だ。
日本企業の調達担当にとっての含意は明確で、エージェント推論の単価境界が動く前提で、現行GPU構成のSLA・粗利を再計算する時期に入った。