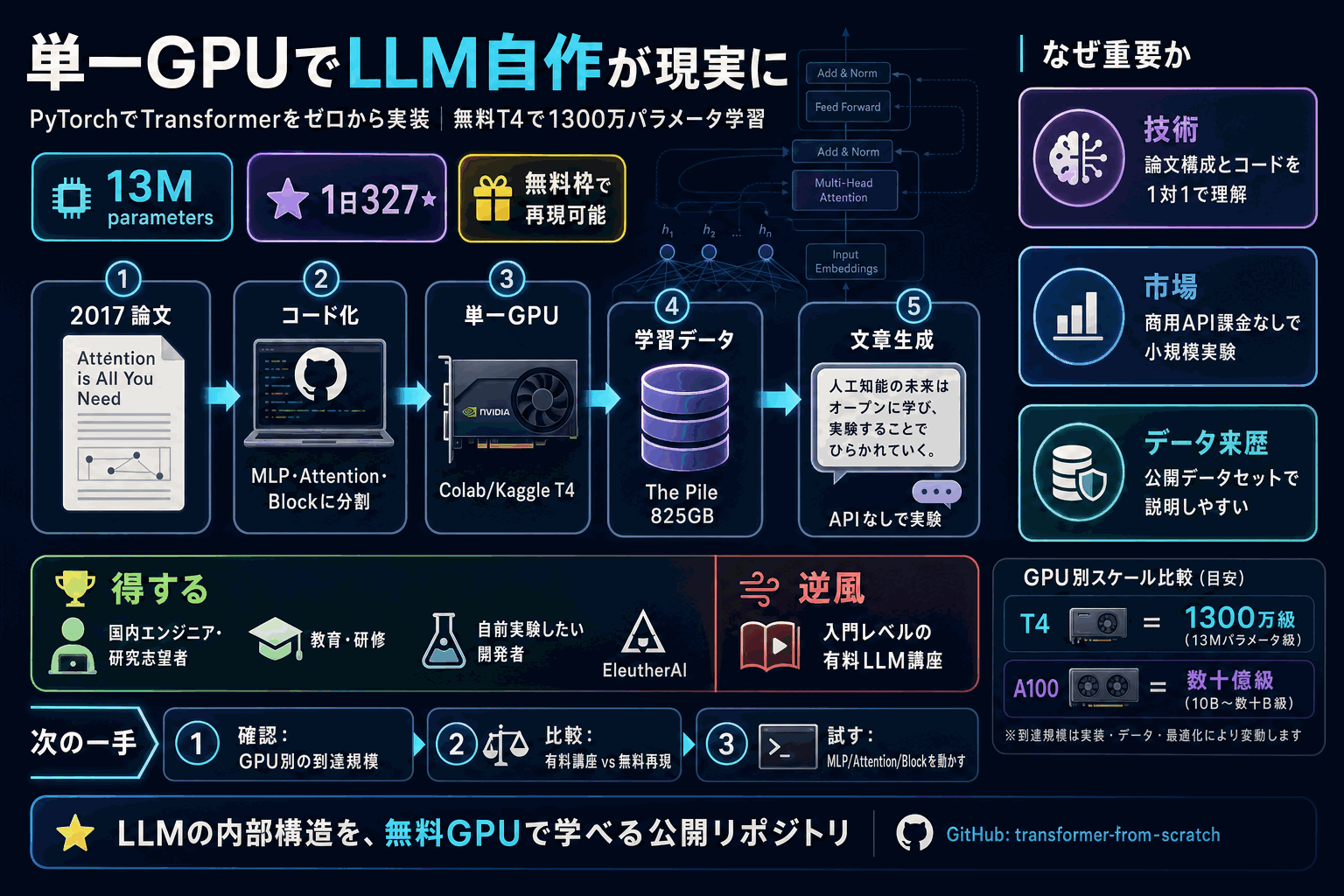
開発者FareedKhan氏が、論文「Attention is All You Need」(arXiv:1706.03762) に基づくトランスフォーマーを PyTorch でゼロから実装したリポジトリ train-llm-from-scratch を公開した。データ取得から文章生成までを単一GPUで完結でき、GitHubトレンドで1日 327スター を集めて急上昇している。
実装は MLP・注意機構・トランスフォーマーブロックの単位にファイル分割され、論文の各構成要素とコードを対応づけて段階的に学べる。学習例として 1300万パラメータ のモデルを学習させ、生成テキストを掲載。学習データには825GBの公開データセット「The Pile」を使う。
注目の要因は参入障壁の低さにある。無料の Colab/Kaggle T4 GPU で1300万パラメータ級が学習可能で、数十億級には A100 等が必要とGPU別の到達範囲を一覧で示している。商用モデルに依存せず原理を理解したいエンジニアや研究志望者にとって、学習の出発点として参照価値が高い。