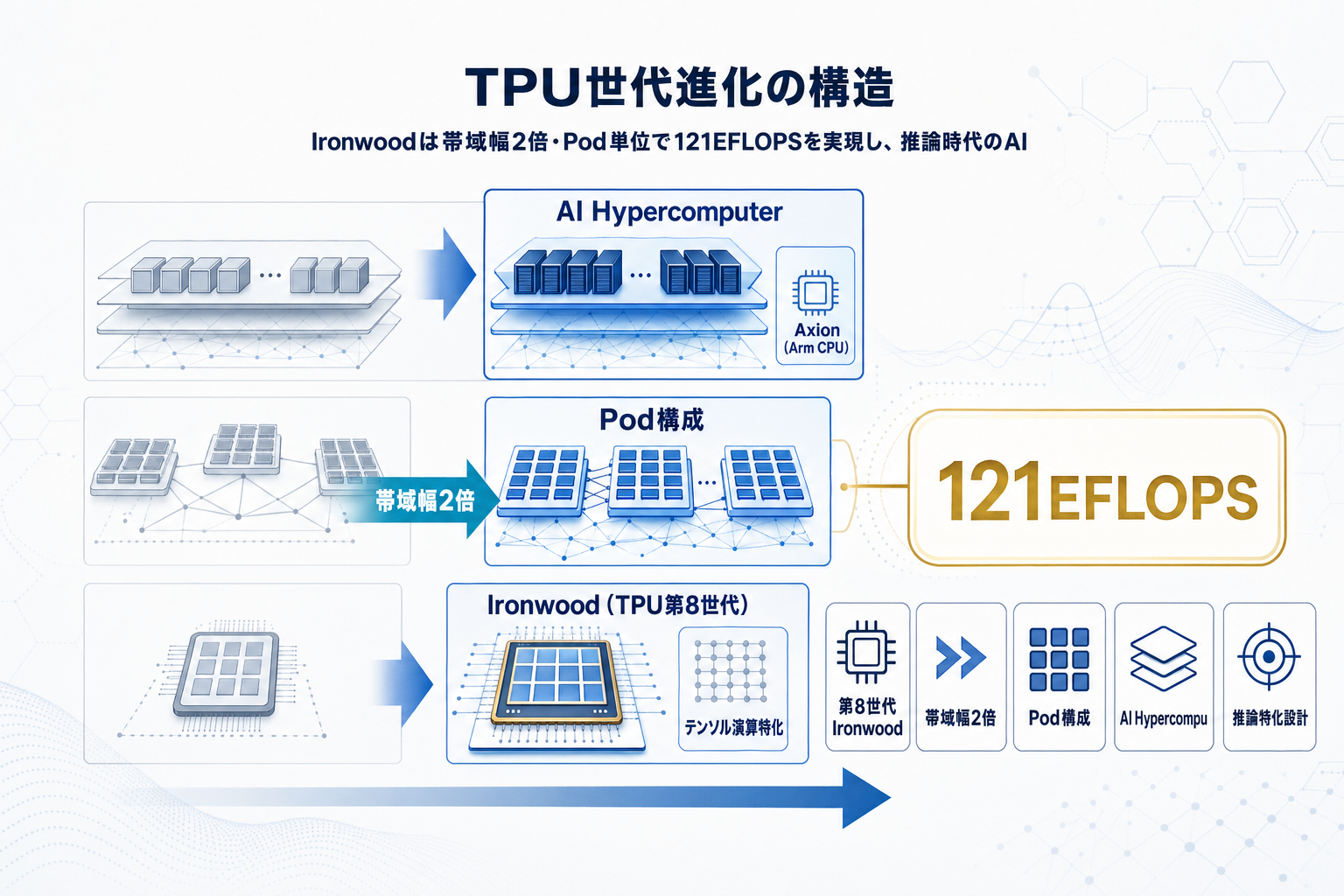
Googleは2026年4月23日、公式ブログで自社設計TPU(Tensor Processing Unit)がAIワークロードをどのように支えているかを解説する新しい動画を公開した。TPUはAIモデルの大規模テンソル演算に特化したアクセラレータで、開発開始から10年以上が経過している。
最新世代の第8世代TPU「Ironwood(TPU7x)」は、Pod構成で121エクサフロップス級の演算能力を提供し、前世代比で帯域幅が2倍に向上している。帯域幅はLLM推論や大規模学習において律速要因になりやすく、ここが2倍になる意味は実装レベルで大きい。単一ジョブで扱えるモデル規模・バッチサイズ・コンテキスト長の上限が押し上げられ、推論コストの構造そのものが変わる。
市場文脈としては、AIアクセラレータがNVIDIA GPUにほぼ一極集中している現状に対し、Google CloudはTPUを自社クラウド経由で提供することで差別化軸を維持している。GPU供給の逼迫と価格高止まりが続く中、TPUは比較対象として現実的な選択肢になりつつある。さらにArmベースの自社CPU「Axion」との組み合わせによる「AI Hypercomputer」構成も並行して訴求されており、CPU・アクセラレータ・ネットワークをコデザインする方向性が鮮明だ。
日本の開発・事業サイドにとっての意味は、調達・設計段階で「GPU前提」の単一仮定を見直せる材料が増えたという点に尽きる。既存のCUDA資産との移植コスト、JAX/XLAスタックの学習コスト、リージョン提供状況を含めて、ワークロード単位で比較検証する段階に入った。