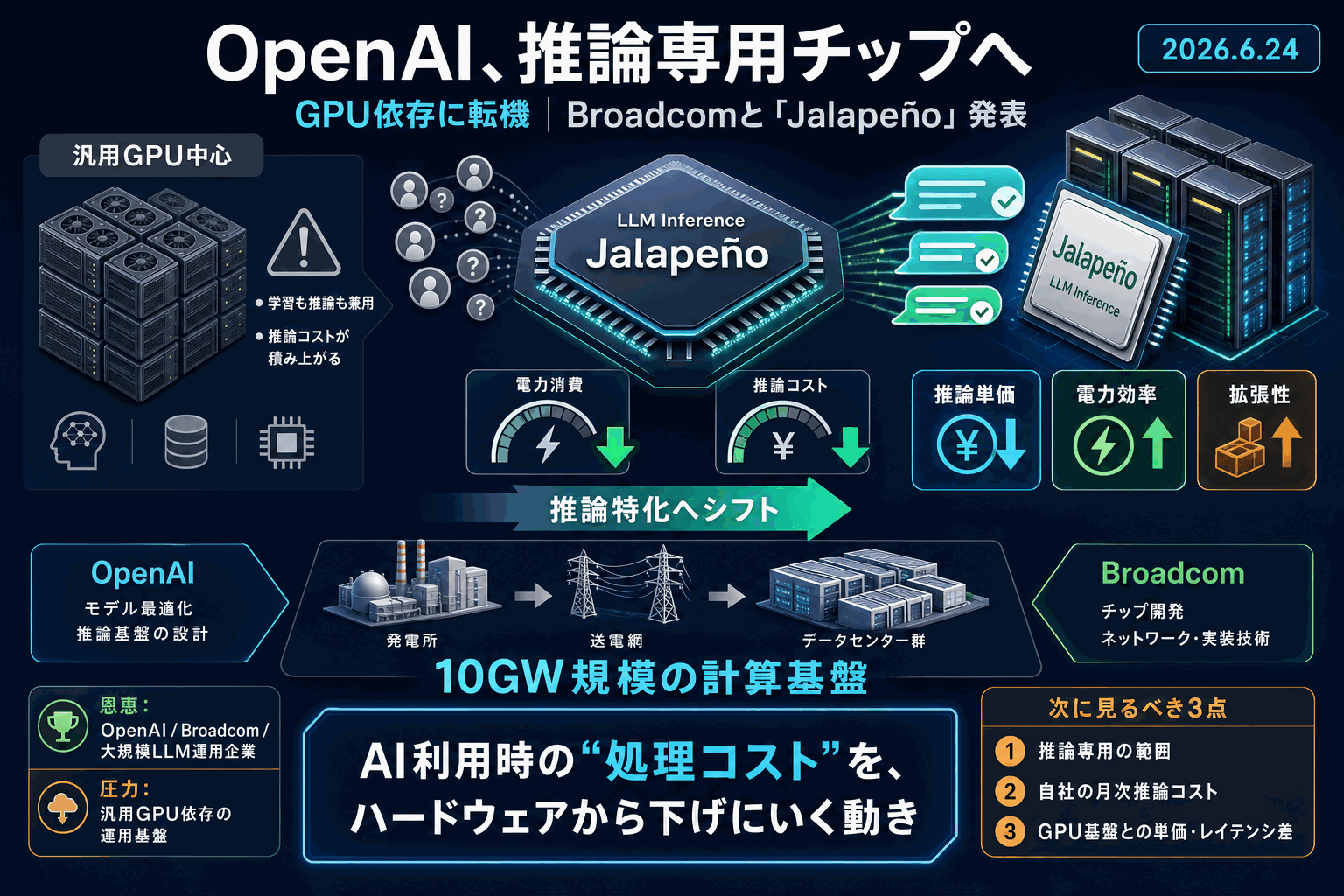
OpenAIと半導体大手のBroadcomが2026年6月24日、大規模言語モデル(LLM)の推論処理に最適化した独自AIチップ「Jalapeño」を発表した。推論とは学習済みモデルが利用時に応答を返す処理を指し、今回のチップは性能・電力効率・処理規模の拡張性の向上を狙った設計である。
AIサービスでは学習だけでなく利用時の推論にかかる電力とコストが急増し、汎用GPUへの依存が課題になっている。OpenAIが汎用GPU一辺倒から独自設計へ踏み出したことは、推論コストをハードウェア側から握りにいく動きである。Jalapeñoは単発ではなく、両社が公表済みの合計10ギガワット規模の計算基盤を展開する協業の延長線上に位置づけられる。
LLMを大規模に運用する企業にとっては、推論コストの構造変化を読む手がかりになる。仕様の詳細な数値は公開段階のため、まず一次ソースで推論専用とされた範囲と協業との関係を確認し、自社の推論単価・電力前提と照らすことが現実的な一手になる。