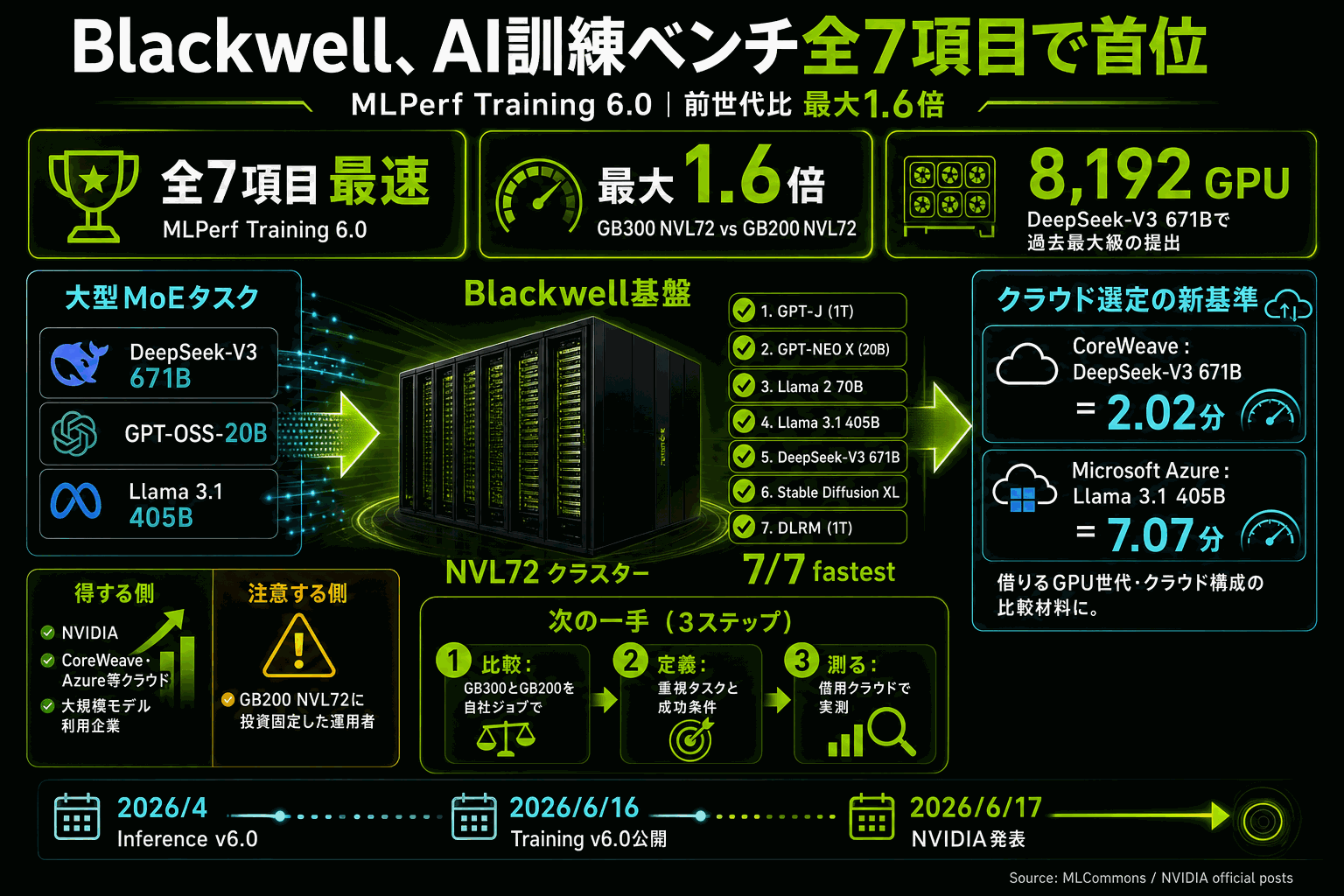
NVIDIAは、AI訓練の性能を測る業界標準ベンチマークMLPerf Training 6.0で、自社のBlackwell基盤が全7項目で最速の訓練時間を記録したと発表した。最大8,192基のGPUを用いた大規模構成にも対応し、全項目に結果を提出した唯一の基盤となった。
今回の核心は、新世代の大型システムGB300 NVL72が同一規模の前世代GB200 NVL72比で最大1.6倍速い訓練性能を達成したことだ。世代更新の効果が具体的な数値で示された。さらに、役割を分けて処理する新方式である混合エキスパート(MoE)の事前学習タスクとしてDeepSeek-V3 671Bなどが追加され、Blackwell基盤はこれで8,192基まで拡張し過去最大規模を提出した。
クラウド事業者の記録も具体的で、CoreWeaveはDeepSeek-V3 671Bを2.02分、Microsoft AzureはLlama 3.1 405Bを7.07分で訓練した。ASUS・Dell・Google Cloud・Fujitsuなど19組織がエコシステムとして結果を提出している。訓練の速さは最先端モデルの投入時期と訓練コストに直結し、世代選定の判断材料となる。